データサイエンスコースのDaichiです。今回はOpenAIから新しい音声認識モデル"Whisper"が公開されたということで色々触ってみることにしました。実際にさまざまな音声で推論を行い、どの程度使えるのかを確認していこうと思います。
目次
- Whisperって何?
- 実際に動かしてみる
- 色々な音声を推論してみる
- まとめ
- 参考文献
Whisperって何?
WhisperはWebから収集した68万時間の多言語音声で学習した汎用音声認識モデルです。大規模で多様なデータセット使用することで過去のモデルと比べてロバスト性が向上しました。
(680,000時間 = 約28333日 = 約78年 ヤバすぎる...)
できることは以下の通り。
- 多言語音声認識
- 音声翻訳
- 言語識別
- 有音無音判定
実際にFleursデータセットの音声を言語別に推論してWER(Word Error Rate:単語誤り率)を計算した結果が下のグラフになります。(これは一部です。)
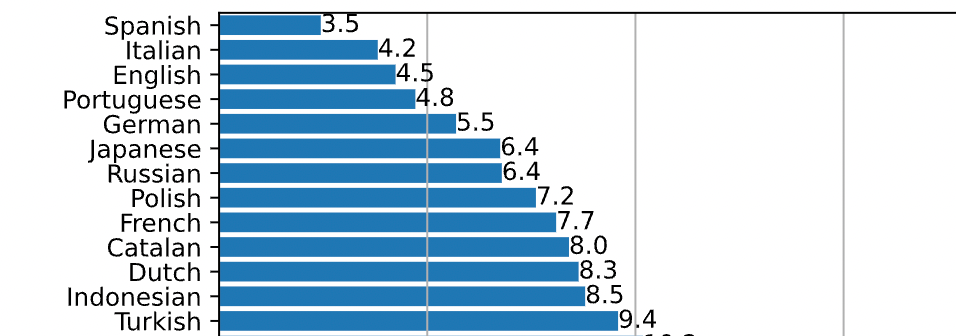
日本語のWERは6.4%とかなり低いです。これは期待できそう..
実際に動かしてみる
実行環境
-
google colab
- GPU: Tesla A100 (GPUメモリ40GB搭載)
- CUDA: 11.2
- メモリ: 12GB(標準タイプ)
-
ライブラリのバージョン
- transformers: 4.22.2
- whisper: 1.0
まずはWhisperのインストールをしていきます。
!pip install git+https://github.com/openai/whisper.git
ライブラリのインポート、モデルのロードしていきます。model_sizeは以下の表の通りです。今回はlargeで推論を行います。

import whisper
model_size = "large"
model = whisper.load_model(model_size)
音声はjvsコーパスのVOICEACTRESS100_001を使います。
コーパスとは音声とテキストが対となっているデータのことです。verbose=Trueは処理過程のログを出すための引数でデフォルトはFalseです。
FileName= "VOICEACTRESS100_001.wav"
result = model.transcribe(FileName, verbose=True)
print(result["text"])
出力は以下のようになります。
Detecting language using up to the first 30 seconds. Use `--language` to specify the language
Detected language: Japanese
[00:00.000 --> 00:08.000] また、当時のように五大明王と呼ばれる主要な明王の中央に排されることも多い。
また、当時のように五大明王と呼ばれる主要な明王の中央に排されることも多い。
最初の30秒を使って言語の特定を行います。その後、言語は日本語と特定され文字起こしが始まります。
result = model.transcribe(FileName, verbose=True, language="ja")
このように言語を指定すると言語の特定は行われません。
[00:00.000 --> 00:08.000] また、当時のように五大明王と呼ばれる主要な明王の中央に排されることも多い。
また、当時のように五大明王と呼ばれる主要な明王の中央に排されることも多い。
ではこの文字起こしの結果と実際のテキストを比較してみます。
また、東寺のように、五大明王と呼ばれる、主要な明王の中央に配されることも多い。(実際のテキスト)
また、当時のように五大明王と呼ばれる主要な明王の中央に排されることも多い。(文字起こし)
「東寺」が「当時」に、「配される」が「排される」になってますね。「東寺」の方は固有名詞なので正しい漢字に起こせなくてもしょうがない気はします。「当時」でも意味は通りますしね...
コード全文
!pip install git+https://github.com/openai/whisper.git
import whisper
model_size = "large"
FileName = "VOICEACTRESS100_001.wav"
model = whisper.load_model(model_size)
result = model.transcribe(FilePath, verbose=True)
print(result["text"])
色々な音声を推論してみる
上から
- 囁き声("whisperって銘打ってるんだからもちろんできるよね!?")
- 裏声
- オノマトペありの声
- 音楽
です!上の三つはjvsコーパスから、音楽は魔王魂からお借りしました。
推論結果はこちらです。上の文章が正しいテキスト、下がwhisperで推論したテキストです。
- 囁き声
母の死は、私の生涯に、大きな空白を残した。
母の死は私の生涯に大きな空白を残した。 - 裏声
ニューイングランド風は、牛乳をベースとした、白いクリームスープであり、ボストンクラムチャウダーとも呼ばれる。
ニューイングランド風は牛乳をベースとした白いクリームスープであり、ボストン・クラムチャウダーとも呼ばれる。 - オノマトペあり
朝から体調が悪く、胃のあたりがキリキリと痛む。
朝から体調が悪く、胃のあたりがキリキリと痛む。 - 音楽
桜の場所で交わした想い桜咲いた美しい世界今は全て忘れて涙ふいて側へおいで光を照らすから
桜の場所で交わした想い桜咲いた美しい世界今は全て忘れて涙拭いて空へおいで光を照らすから
句点を読み取れていない部分がありますがそれでも圧倒的な結果です。今回使ったような良質な音声ではほとんど100%と言っていいほどの精度を出せるようです。
まとめ
whisperいかがだったでしょうか。
めんどくさい文字起こしの作業をたった数行で自動化できるのはかなり魅力的です。私はwhisperを使って英語の授業の予習をしています。これを読んだ方も是非使ってみてください。読んでくれてありがとうございました。
参考文献
whisperのgithubリポジトリ
whisper作成者のブログ
jvsコーパス
魔王魂 KoKoRo Blossom




{kind=link}