データサイエンスコースに所属している竹下隼司です。最近勉強した音声処理の実践を兼ねて、音声の声質(裏声、囁き声など)を分類する決定木モデルを作成していこうと思います。
目次
- ライブラリ類の準備
- データセットの準備
- 音響特徴量の抽出
- 学習
- 評価
- まとめ
- 参考文献・クレジット
ライブラリ類の準備
実行環境は、Colaboratory (python==3.8.16)を想定しています。
主に使うライブラリは、pyworld, librosa, scikit-learnです。
!pip install -qqq pyworld |████████████████████████████████| 214 kB 4.8 MB/s
Installing build dependencies ... done
Getting requirements to build wheel ... done
Preparing wheel metadata ... done
Building wheel for pyworld (PEP 517) ... done
from pathlib import Path
import numpy as np
import librosa # 音声処理
import pyworld as pw # 音声処理
from tqdm import tqdm
from sklearn.preprocessing import minmax_scale
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn import metrics
import matplotlib.pyplot as plt
%matplotlib inlineデータセットの準備
今回使用する音声データである、JVSコーパスという100話者の日本語音声コーパスをダウンロードします。gdownというライブラリでGoogleDriveからダウンロードしています。
ダウンロード時のエラー回避のため、gdownをアップグレードしていることに注意してください。[1]
!pip install -qqq --upgrade gdown
!gdown "https://drive.google.com/uc?export=download&id=19oAw8wWn3Y7z6CKChRdAyGOB9yupL_Xt"
!unzip /content/jvs_ver1.zipデータには以下のような、音声コーパスが含まれています。
parallel100: 話者間で文章が共通する読み上げ音声100発話nonpara30: 話者間で文章が異なる読み上げ音声30発話whisper10: ささやき声10発話falset10: 裏声10発話
このうち、parallel, whisper, falsetの3種類の声質について、各100話者から10発話ずつ取りだして、データセットを作成していきます。
dataset_path = Path("/content/jvs_ver1")
jvs_number_list = [str(s).zfill(3) for s in range(1, 101)]
voice_pattern_list = ["falset10", "parallel100", "whisper10"]
dataset = []
for num in jvs_number_list:
for voice_pattern in voice_pattern_list:
file_list = list(dataset_path.glob(f"jvs{num}/{voice_pattern}/**/*.wav"))
dataset.extend(file_list[:10])
print(f"音声数:{len(dataset)}")音声数:3000
学習データの内訳は、parallel, falset, whisperの音声がそれぞれ1000件ずつです。
音声の可視化と比較
声質間を比較するために、声質ごとの基本周波数(F0)と可視化します。
可視化には、単一話者の異なる声質間で文章が共通している音声の前から3秒間ずつを切り取っています。
plt.figure(figsize=(10, 4))
for idx, voice_pattern in enumerate(voice_pattern_list):
filepath = dataset_path / "jvs001" / voice_pattern / "wav24kHz16bit/VOICEACTRESS100_001.wav"
x, sr = librosa.load(filepath, sr=22050, mono=True)
x = x.astype(np.float64)[:sr*3]
_f0, t = pw.dio(x, sr)
f0 = pw.stonemask(x, _f0, t, sr)
vuv = (f0 > 0)
plt.plot(t, f0, label=voice_pattern, linewidth=3)
plt.title("Frequency")
plt.xlabel("Time [s]")
plt.ylabel("Frequency [Hz]")
plt.legend()
plt.tight_layout()
plt.show()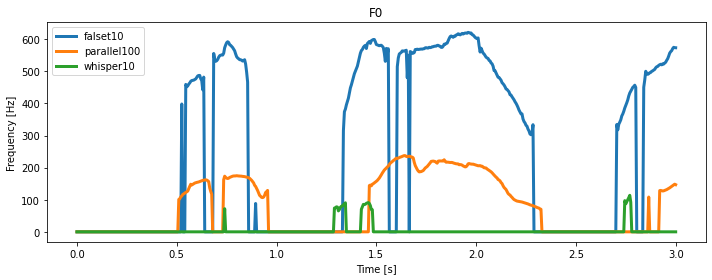
可視化結果から、以下のことが読み取れます。
- 声質間で、基本周波数(
F0)の大小が見られ、大きい順にfalset,parallel,whisperになっている。 - 声質間で、無声部分(
F0=0)の割合の高低が見られ、whisperが他の声質に比べて、特に割合が高くなっている。
感覚的に、裏声(falset)は高音で基本周波数が高く、囁き声(whisper)は息が多くて無声音の割合が高いというのは分かる気がします。
以上の考察から、今回の3つの声質を分類するには、基本周波数の特徴が利用できそうです。では、実際に抽出する音響特徴量を見ていきましょう。
音響特徴量の抽出
学習モデルに入力する特徴量として、音声から以下の4つの音響特徴量を抽出します。
1. 基本周波数(F0)の平均
2. 抑揚の平均
3. 有声部分の割合
4. MFCCの平均
ここでの抑揚とMFCCは、どちらも以下のような周波数に関する特徴になっています。
* 抑揚:基本周波数について、平均からの偏差の絶対値
* MFCC:周波数スペクトルを人間の聴覚特性(メル尺度)に合うように対数変換を施した信号に関する特徴。[2]
次に、音響特徴量抽出の実装には、pyworldとlibrosaを利用します。
def extract_acoustic_features(filepath):
x, sr = librosa.load(filepath, sr=22050, mono=True)
x = x.astype(np.float64) # 音声信号
_f0, t = pw.dio(x, sr)
f0 = pw.stonemask(x, _f0, t, sr) # F0
mfcc = librosa.feature.mfcc(y=x, sr=sr, n_mfcc=20, dct_type=3) # MFCC
f0_vuv = f0[f0 > 0] # 有声・無声フラグ
vuv_ratio = len(f0_vuv)/len(f0) # 有声部分の割合
if vuv_ratio != 0:
f0_mean = np.mean(f0_vuv) # F0
intonation = np.abs(f0_vuv - f0_mean) # 抑揚
intonation_mean = np.mean(intonation) # 抑揚の平均
else:
# 要素がない配列について平均を取る場合
f0_mean = 0
intonation_mean = 0
mfcc_mean = np.mean(mfcc) # MFCCの平均
return (vuv_ratio, f0_mean, intonation_mean, mfcc_mean)この関数を用いて、データセットに前処理・特徴量作成をしていきます。
学習
声質分類に使用するモデルは、ランダムフォレストという決定木モデルを使用します。初めに、以下の関数で、学習評価用にデータセットを作成します。
def get_voice_pattern(filepath):
return filepath.parts[-3]
def load_dataset(dataset, voice_pattern_list):
X, y = [], []
voice_pattern_dic = {"falset10": 0, "parallel100": 1, "whisper10": 2}
for filepath in tqdm(dataset):
voice_pattern = voice_pattern_dic[get_voice_pattern(filepath)] # 正解ラベルを数値へ変換
acoustic_features = extract_acoustic_features(filepath)
X.append(acoustic_features)
y.append(voice_pattern)
return train_test_split(np.array(X), np.array(y), test_size=0.2)voice_pattern_list = ["falset10", "parallel100", "whisper10"]
X_train, X_test, y_train, y_test = load_dataset(dataset, voice_pattern_list)
print(f"訓練データ:{X_train.shape}")
print(f"テストデータ:{X_test.shape}")
print("テストデータ内のラベル割合")
for label, counts in zip(*np.unique(y_test, return_counts=True)):
print(f"{label}: {counts}件", end=" ")100%|██████████| 3000/3000 [20:38<00:00, 2.42it/s]訓練データ:(2400, 4)
テストデータ:(600, 4)
テストデータ内のラベル割合
0: 196件 1: 204件 2: 200件
学習データを訓練用2400件、テスト用600件に分割しています。
テストデータ内のラベル割合を見ると、ラベルがほぼ均等に含まれていますね。
次に、訓練データを用いて、ランダムフォレストによる分類モデルを学習します。モデルの引数は、sklearnのデフォルト設定にしています。
model = RandomForestClassifier(n_estimators=100)
model.fit(X_train, y_train)RandomForestClassifier()
評価
デフォルト設定のランダムフォレストで、どれくらいの精度で声質を分類できているか確認していきます。
1. 正解率(Accuracy)
y_pred = model.predict(X_test)
metrics.accuracy_score(y_test, y_pred)0.9633333333333334
テストデータ600件について、96%正しく予測できています!
2. 混合行列(Cofusion Matrix)
具体的にどの声質が、正解/不正解だったのでしょうか。混合行列を用いて確認します。
metrics.confusion_matrix(y_test, y_pred)array(
[[173, 10, 0],
[ 12, 196, 0],
[ 0, 0, 209]])
今、インデックスは、falset, parallel, whisperの順になっています。
結果から、裏声(whisper)は全て正解、通常の声質(parallel)と裏声(falset)は、お互いに誤って予測しているものが、どちらも10件程度確認できます。
3. 特徴量の重要度(Feature Importance)
決定木モデルは、特徴量が、学習時の枝の分割にどれだけ関与しているかを示す重要度という指標があります。作成した4つの音響特徴量の内、どれが声質分類に大きく寄与していたのでしょうか。
plt.figure()
plt.title("Feature Importance")
plt.barh(["V/UV Ratio", "F0 Mean", "Intonaiton Mean", "MFCC Mean"], model.feature_importances_)
plt.show()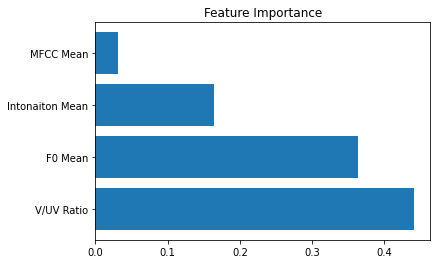
重要度が最も高い特徴量は、有声部分の割合(V/UV Ratio)で、基本周波数の平均(F0 Mean)が同じくらい高くなっています。
逆に、MFCCの平均(MFCC Mean)は、ほとんど寄与していないことがわかります。
まとめ
- 裏声(
falset)、通常発声(parallel)、囁き声(whisper)を96%正しく分類することが出来ました。 - この実験から、裏声(
falset)や囁き声(whisper)の違いは、有声部分の割合や基本周波数の平均の大小の違いに深く関係していることが考察できました。
[1] 【重要】Google colabでgdown使用時のエラー のエラーを回避してます。
[2] LibROSA で MFCC(メル周波数ケプストラム係数)を算出して楽器の音色を分析の解説が参考になりました。
参考文献・クレジット
学習データには、高道 慎之介様が公開している音声データを使用しています。
JVS (Japanese versatile speech) corpus




{kind=link}