アドベントカレンダー12日目!
データコースで音声合成に関する案件に参加しているSotaです。
最近、VRChatで声も姿もずんだもんの方に会い、姿の方はアバターを変えればいいのですが、声をどうしているのか気になり聞いてみました。そしたら、MMVCっていうのを使ってるのだと教えてもらえました。
会話にほぼ遅延が感じられず、声自体もずんだもんそっくりでした。
今回の記事は、そんなMMVCを使ってみたという内容です。
やることが多いので、細かい所までは説明せず、サクサク書いていきます。

MMVCとは
AIを使ったリアルタイムボイスチェンジャー「MMVC(RealTime-Many to Many Voice Conversion)」
です。(公式ドキュメント から引用)
AIの部分には、VITS という2021年6月に公開されたばかりの音声合成モデルが使われています。自分が現在参加させていただいている案件でもこのモデルを利用しています。
音声合成はTTS(Text to Speech)と呼ばれ、テキスト → 音声に変換することを指しますが、VITSは音声変換(STS: Speech to Speech)にも使うことができ、MMVCは音声変換の方を利用しています。VITSの解説記事 にある推論時(テキスト読み上げ)と推論時(音声変換)の2つの図がとても分かりやすいので、VITSに興味がある方はぜひ読んでみてください。
補足:音声変換はSTS(S2S)より、ボイチェンやVCと呼ばれてる方が一般的だと思います。
MMVCのモデル作成手順
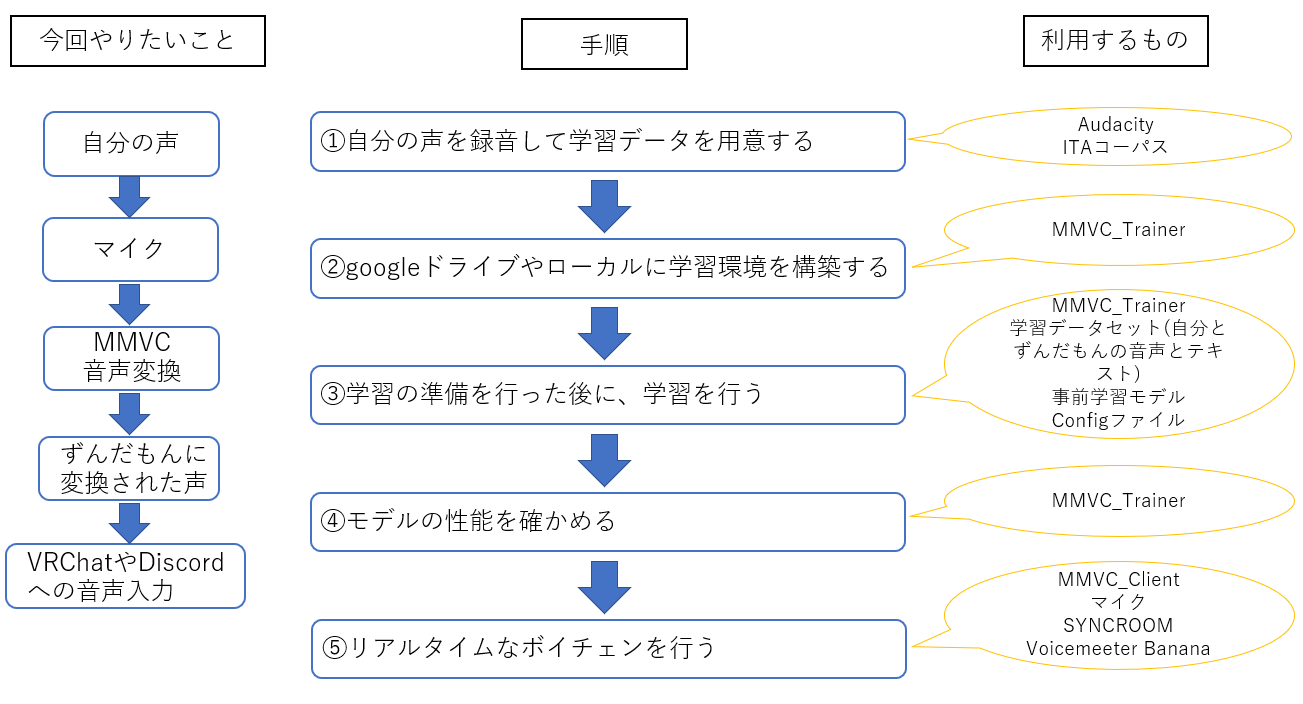
おおまかには画像のような流れです。
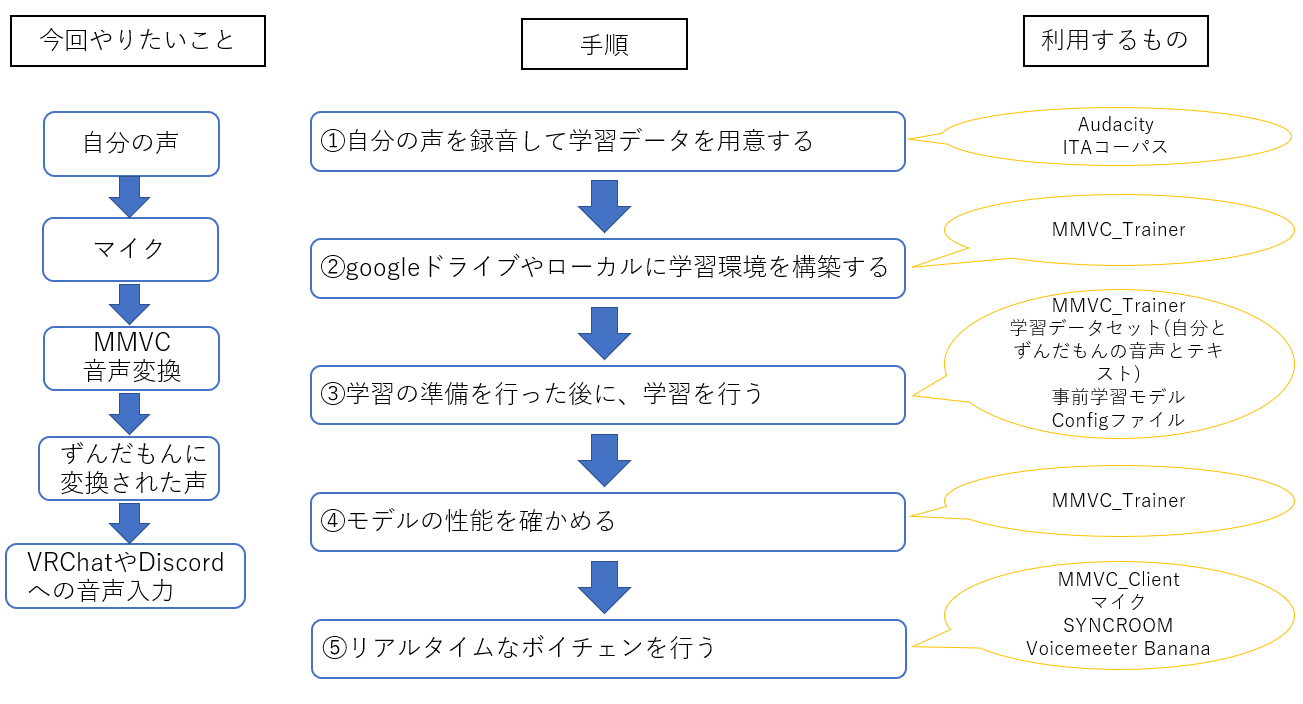
各手順を具体的にどう進めていくのかに関しては、以下の資料や動画を参考にしてください。
- 公式ドキュメント
- MMVC_Trainer:学習手順もREADMEに記載されている
- MMVC_Client:学習モデル作成後以降の手順がREADMEに記載されている
- MMVC導入解説動画:過去の情報になっているものもあるため、動画を見ながら進める場合は、最後(最新)の動画も同時に見ること推奨
- Discordサーバー:ライブラリ開発者や解説動画の作成者さんがアクティブで質問にもすぐ回答してくれるため、とりあえず入っておくこと推奨
- ボイチェン方法に関して:ボイチェン音声を相手に伝えるためには、マイクを入力にするのではなく、ボイチェン後の音声を入力として渡す必要がある。自分が想定していなかった最後の障壁で、記事作成段階でまだ模索中
現段階で作成できたモデルを用いて変換した音声
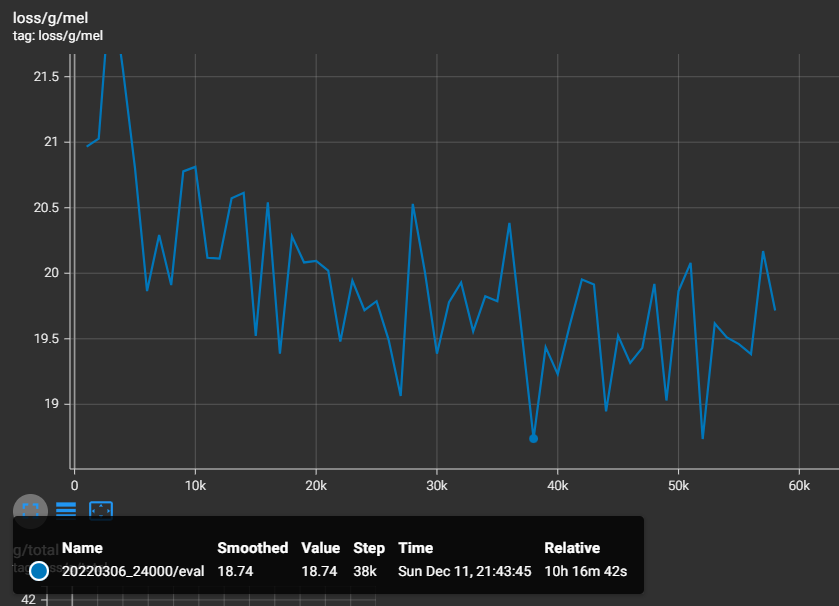
モデルの選択基準ですが、解説動画ではeval(評価用データ)に対するloss/g/mel(generatorのmel loss)の値が19を下回ってくればgoodという説明がありましたが、実際に推論(音声変換)してみるまでは分からないそうです。
generatorのmel lossは論文内の言葉でいうとReconstruction loss(再構成損失)にあたる損失だと思われます。音声合成の方でもKL divergence lossなど他の損失が上がっていくことを許容してでもこのReconstruction lossが下がるように損失関数ごとの重み係数を設定しています。そのくらいVITSの学習において、Reconstruction lossが大事なんだと分かります。
話を元に戻しますが、昨日12時間程度学習した中で、evalのloss/g/melの値が18.74のモデルが出来たので、このモデルを使って音声変換をテストしてみました。
ITAコーパス emotion_006 テキスト
- ストラットフォード・オン・エイヴォンは、シェイクスピアの生まれたところですが、毎年多くの観光客が訪れます。
ITAコーパス emotion_011 テキスト
- イタリア旅行で彼は、いくつか景勝の地として有名な都市、例えば、ナポリやフィレンツェを訪れた。
感想と今後やりたいこと
音声はどうでしたでしょうか?個人的にはただ手順通りに学習を進めただけでも結構いい音声になり、流石VITSだなという感じでした。
今後は、SYNCROOMやVoicemeeter Bananaというソフトに触ったことがなく、リアルタイムのボイチェン導入がまだ上手くいっていないので、まずこれをやりたいです。
その後は、今回MMVCの学習環境をローカルでも構築したので、そのやり方を記事にしたり、自分の音声データセットをITAコーパス100文から、ITAコーパス424文に増やして再学習をしたりしていきたいです。
最後まで読んでくださりありがとうございました。




{kind=link}