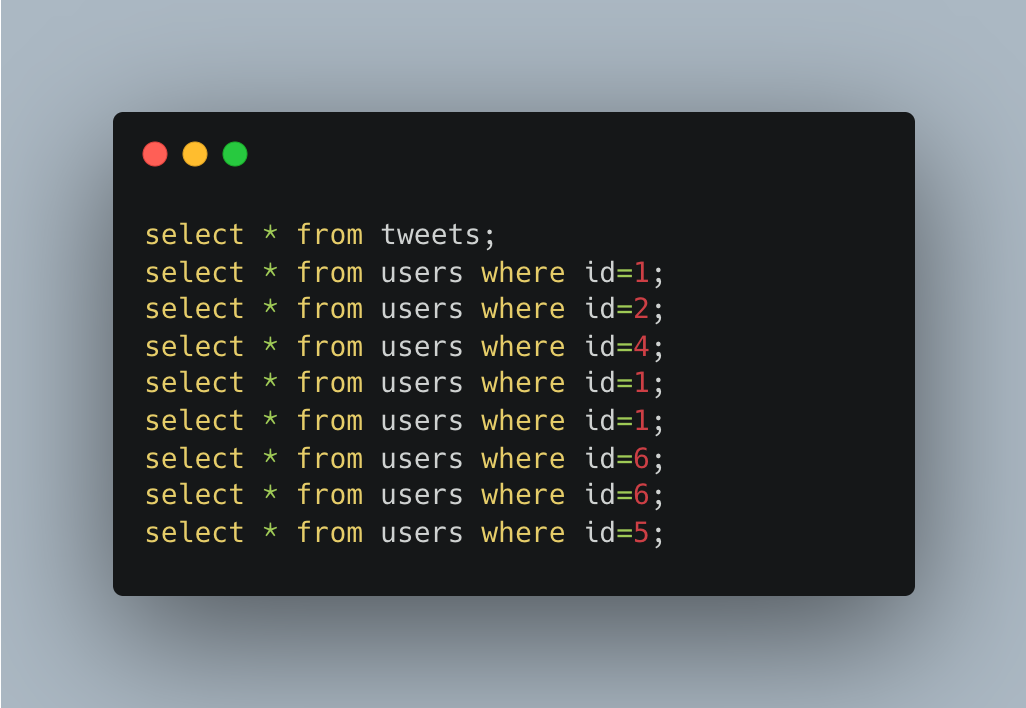
アドベントカレンダー3日目です!
バックエンドコースで運営をしつつ,モバイルコースにも所属しているTAK848です。今回は,DjangoのようなO/Rラッパーを使う際にも是非知っておいてほしいDBの基礎知識,SQLの基本,N+1問題まで,Djangoの例も交えながら書きたいと思います。
ハンズオンもありますので,ターミナル操作に慣れていて動かせる環境があれば,是非動かしてみてください。
DBの基礎知識
DB(データベース)にもNoSQLやRDBといった色々なものがありますが,今回は一番一般的とも言えるRDBについて記述します。
RDBとは,Relational DataBaseの略で,エクセルみたいな表が何個かあり,複数のテーブルをIDなどの一意の値で紐づけて関連を表現しつつデータを保存できるデータベースです。
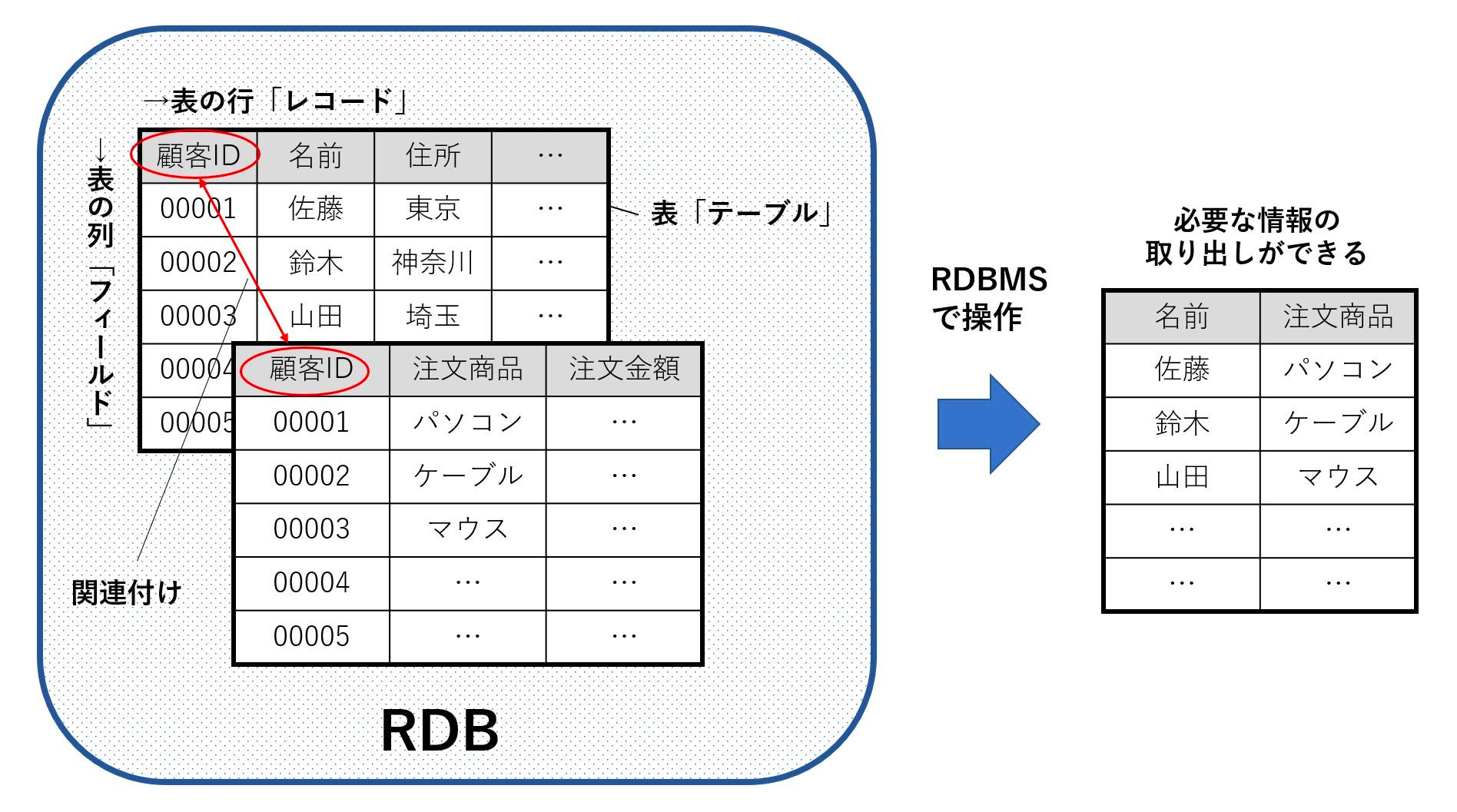
用語
RDBに欠かせない用語を一通り列挙します。誰でも馴染みがある程度あると思うので,エクセルを使って例えたいと思います。引用した上の図も参考にしてみてください。
テーブル
エクセルでいうシートで,1枚1枚をテーブルという
カラム
エクセルでいうと列。列には同じ種類のデータが入る(int: 整数だったり,varchar: 文字列だったり)
レコード
エクセルでいう,行
1レコードで,基本一連の1つのデータの塊を表す
例えば上の画像のユーザーのテーブルでいうと,顧客IDが00001番の佐藤さん,住所が東京…で1レコード
フィールド
エクセルでいう,入力枠一つ一つの要素
例えば顧客ID2番の人の注文商品はケーブルで,このケーブルは一つのフィールド
PK(プライマリーキー )
レコードを一意に指定できるフィールド名(複数1セットのこともある)
主にこの一意のIDを使ってテーブルの繋がりを表現できる(Tweetテーブルの中に,user_idというフィールドを作り,ユーザー番号経由で参照する,など)
DjangoのModelはデフォルトで,データ作成ごとに1増えるBigAutoFieldがPKとして設定されている(もちろん自分でUUIDFieldに変更もできる)
RDBMS
RDBを運用するのに,SQLiteやMySQL,PostgrSQLといった,「RDBMS」(Relational DataBase Management System)を用いる
SQLite以外は,データベースをサーバーとして立てておいて,ネットワーク経由で接続するという形式をとる(Djangoで例えると,データベース版のrunserverをずっとしているようなイメージ)
SQLiteは,簡易で簡単に利用できる管理システムで,Excelでいうxlsxファイルみたいにファイルがあり,そのファイルを読み書きする(=サーバーがいらず,とりあえず使用したい時や,モバイルアプリなどでデータを管理したい時でも使う)
SQL
データベースに保存されたデータを閲覧したり,書き込んだりするにはSQLという言語を使う
SQLに国際規格はあるものの,RDBMSによって方言があるのが困りもの(一番標準的なのはPostgreSQL,個人的に扱いやすいのはMySQL)
Djangoでは,SQLを意識しなくて良いように,Modelという概念で扱えるようになっている。 SQLを直接書かずに同様の操作ができるようにラップされており, O/Rラッパーと呼ばれる
SQLiteでRDBを作成・閲覧・操作する
ここからは,SQLiteをコマンドラインから操作してSQLを実行してみましょう!
もし手元でやってみたければ,Windowsの方は[こちら](https://self-development.info/windowsに最新版sqliteをインストールする/)を参考にしてみてください。
macの方はデフォルトでインストールされているので,特段の処理は不要です。[こちら](https://www.task-notes.com/entry/20140720/1405845794)なども参考に。
実行方法
sqlite3 hogehoge.sqlite3
のように書くと,カレントディレクトリに hogehoge.sqlite3 が生成され,SQLiteでSQLを実行できるようになります。
すでに存在しているファイルでももちろんOKです。(Djangoのチュートリアルこなした方は, manage.py と同じ場所に db.sqlite3 もあるので, sqlite3 db.sqlite3 で実行してみましょう)
ちなみに,
sqlite3
のように引数がなしで実行すると,メモリ上でデータは管理され終了するとデータは消えます。今回みたいに簡易的に実行したいときは,こちらでOKです。
終了方法
SQLiteのコンソールから抜けたい時は,
.exit
を実行してください。(SQLite独特の書き方。.xxxxみたいなコマンドがSQLiteは多い)
テーブル作成(例)
sqlite3 を実行しただけでは,まだ何もデータが入っていません。まずはテーブルを作ってみましょう。 CREATE を利用します。
-- CREATE文でusersテーブルを作成
CREATE TABLE `users` (
`id` INT PRIMARY KEY,
`name` VARCHAR(50),
`age` INT
);usersという名前のテーブルを,INT型のid,50文字以内の文字列のname,INT型のageという3つのカラムを用意して作成しました。
SQLiteでテーブル一覧を確認したい時は,
.tablesを実行してみましょう。すると, users と帰ってきます。
データ挿入(例)
テーブルを作成したら,次はデータを挿入しましょう。 INSERT を利用します。
-- INSERT文でusersテーブルのレコードを作成
INSERT INTO users(id,name,age) VALUES(1,'PG1',22);
INSERT INTO users(id,name,age) VALUES(2,'PG2',23);
INSERT INTO users(id,name,age) VALUES(3,'PG3',25);
INSERT INTO users(id,name,age) VALUES(4,'PG4',27);
INSERT INTO users(id,name,age) VALUES(5,'PG5',21);
INSERT INTO users(id,name,age) VALUES(6,'PG6',21);データ取得(例)
最後にせっかく挿入したデータを取得してみましょう。 SELECT を利用します。
-- 全てのカラムの全レコードを取得
SELECT * from users;
-- name, ageのカラムを全レコード取得
SELECT name, age from users;
-- idが1のレコードの全カラム取得
SELECT * from users where id=1;以上のように, SELECT 文を用いて様々な形で必要なデータを絞り表示することができます。
例えば実行結果は以下のようになります。
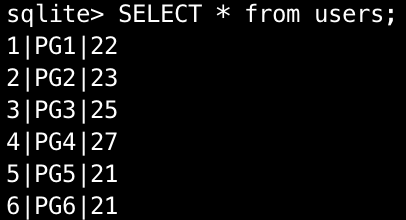
最初に登録したデータが全部表示されていますね。
他にも3つ目の例の実行結果は以下のようになり,id=1のみを表示できました。

他にも色々なことができますが,今回はこれくらいに留めておきます。SQLによる操作は,世の中にたくさん記事があるので調べてみてください。
N+1問題とは?
初めてバックエンドでアプリを作るときに引っかかりがちな,N+1問題について解説していきます。
一般に,SQLは,1回の実行に時間がかかります。また,SQLを大量に発行するとその文ネットワークの帯域も使います。そのため,パフォーマンスを落とさないためにも基本的には無駄にたくさんのSQLが発行されるのは避けたいです。
では実際に,先ほどのusersのテーブルにtweetsというテーブルを加えたサンプルを見てみましょう。
サンプルデータの作成
Tweetsのデータサンプル(この例のように,INSERTは一つにまとめることができ,「バルクインサート」と呼ばれます。)
-- CREATE文でtweetsテーブルを作成
CREATE TABLE `tweets` (
`id` INT PRIMARY KEY,
`content` VARCHAR(140),
`user_id` INT
);
-- INSERT文でtweetsテーブルのレコードを作成
INSERT INTO tweets(id, content, user_id) VALUES(1,'content1',1),
(2,'content2',2),
(3,'content3',4),
(4,'content4',1),
(5,'content5',1),
(6,'content6',6),
(7,'content7',6),
(8,'content8',5);以上で,idをpkとし,140文字以内のcontentと,外部キーとしてuser_idとした3つのカラムをもつtweetsテーブルを作成し,8個のツイートを作成しました。
Tweetのタイムラインを作ろう
ここで,あなたはTweetのタイムラインを作りたくなったとします。それぞれのツイートには,user_idだけではなくてuserの名前も一緒に取得したいです。さて,どうしましょうか。
では,Tweetを一旦全部取得し,selectのさらにユーザーの情報も取得しようとすると?
--- tweetsを取得
select * from tweets;まずは,全Tweetを取得します。
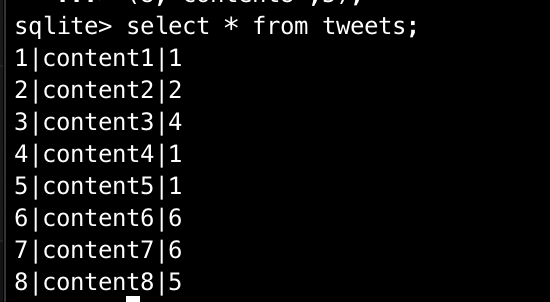
上の画像のようにuser_idが得られたので,ユーザーの情報をそれぞれ取得すると,以下のようになります。
-- それぞれのuser_idのユーザーも取得しよう!
select * from users where id=1;
select * from users where id=2;
select * from users where id=4;
select * from users where id=1;
select * from users where id=1;
select * from users where id=6;
select * from users where id=6;
select * from users where id=5;......
Tweetの数だけ,usersのselect文を発行してしまいました...
tweetsが8個(N=8)あるので,user情報の取得を8回行なってしまい,最初のtweets全取得と合わせると,
N+1=8+1=9回ものSQLが発行されてしまいました。あとはNが増えていくと...恐ろしいですね。
N+1問題を解消しよう--「JOIN」
この対処方法として,JOINを使うという方法があります。
以下の例をみてください。
SELECT * FROM tweets INNER JOIN users ON tweets.user_id = users.id;
上のように,JOINを用いることで,tweetsのuser_idとusersのidが一致している箇所のuserデータをtweetsの結果に含めることができます。結果として下の図のようになります。
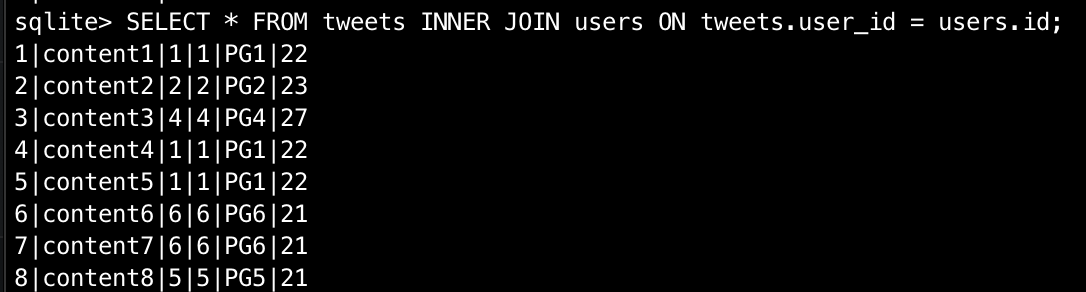
Tweetの中身とセットで,左側にユーザーの情報も入ってきて,ユーザー名も同時に取得できましたね!
このように,RDBMSの強みを活かして,処理を高速化していきましょう!
さらにパフォーマンスを深掘りしたい方は,インデックスについても調べてみてください!
DjangoのコードでもN+1を解消してみる
用語のSQLの箇所でも書いたように,DjangoではSQLを直接触ることはないものの,O/Rラッパーによって隠れているだけで裏ではSQLが発行されています。
よくやってしまいがちなコードとして,以下のような例を見てみましょう。
tweets = Tweet.objects.all()
# SELECT * from tweets;
for tweet in tweets:
print(f'{tweet.content} @{tweet.user.name}') # user.nameを引っ張るときにN+1問題
# SELECT * from users where id = [それぞれのtweetのid];
Tweetsをそのままfor文に何の工夫もなくかけてしまうと,tweetごとにuserの情報をSELECTしてしまい,上述してきたN+1問題が無意識に発生してしまいます。
この解決策としてDjangoでは select_related というものがあり,これによってtweetの全取得時にuserの情報を自動でjoinして取得しておいてくれます。
Tweet.objects.all().select_related('user');
# SELECT * FROM tweets INNER JOIN users ON tweets.user_id = users.id;
for tweet in tweets:
print(f'{tweet.content} @{tweet.user.name}')
# すでに情報を取得済みでN+1問題にならないこれにより,すでにuser.nameの情報は持っているのでSQLは発行されず,N+1問題を解決できます。
段々慣れてきたら,Djangoが実際に発行するSQLをログとして出力してみたり,

django-debug-toolbar
を使用したりすることで,SQLの発行ログが見られるので,このページめちゃめちゃ遅いんだけど…とならないように,異常に発行されているSQLがないかを常に確認するようにしましょう。
For more info
環境構築など気にせずSQLに触れてみたい場合は,Progateや,

最近話題となったSQLabもおすすめです。
書籍としては,
 ミック
ミック
が非常にわかりやすく基本がまとまっていておすすめです。
他にもテーブル設計や,これ以外のチューニングなど,学ぶべきことはたくさんあるので,是非調べてみてください。
ガチでチューニングしたくなったらISUCONは良いぞ
最後に
DBとはどんなものかの説明から,SQLでの操作,N+1問題まで駆け抜けて行きましたが,いかがだったでしょうか。また機会があれば,Django+Dockerの環境構築や,CI/CD関連の記事などを書いてみたいと思います。
ここまでお読みいただきありがとうございました!
明日は,社員デザイナーのAkie Ryuさんです!ワクワク!お楽しみに!
参考文献
サンプル作成などで,以下のサイトにお世話になりましたのでお礼申し上げます。
 Sanshiro Wakizaka
Sanshiro Wakizaka







{kind=link}