
こんにちは。PlayGroundでNext.jsを用いたweb開発のゼミを運営しているluckです。よろしく。
昨今のフロントエンド界隈では、htmxやHotwireといったReact以外の選択肢が注目を集めるようになり、その流れの中で「React不要論2026」などの記事も出てきて、体感として、Reactへの風当たりはかなり強くなってきていると感じる。
Reactはもちろん銀の弾丸ではない。しかし、htmxやHotwireで「代替」されるようなものでもない。それぞれが解こうとしている問いが違う。
そして、React批判の多くに共通しているのは、フロントエンドがどのような歴史を経て今の形にたどり着いたのかを踏まえていないことだ。バニラJSやjQueryの時代に何が辛く、なぜReactが必要とされたのか——その文脈が抜け落ちたまま「Reactは不要だ」と言われている。人類はReactの発明を忘れてしまったようである。
この記事では、Web黎明期からReact、そしてポストReact時代に至るフロントエンド技術の変遷を辿り直す。今一度、Reactはなぜここまで浸透したのか、その貢献とは何だったのかを思い出そう。
第1部: Reactが生まれるまで — 何が辛かったのか
前提知識: webの歴史
まずはwebの歴史を押さえておこう。その前に、そもそもWebがどうやってページを表示しているかを確認しておく。
Webの基本的な仕組み
ブラウザにURLを入力してページが表示されるまでに、裏側では以下のことが起きている。
1. URLからサーバーの場所を特定する
ブラウザは「example.com」というドメイン名を、DNS(Domain Name System)という
仕組みを使って「93.184.216.34」のようなIPアドレスに変換する。
IPアドレスはインターネット上のコンピューターの住所のようなもので、
これにより「どのコンピューターに問い合わせればいいか」が分かる。
2. そのサーバーにリクエストを送る
「https://example.com/about のページをください」
3. サーバーがHTMLを返す
サーバーとは、リクエストを受け取ってデータを返すコンピューターのことだ。
世界中のどこかにあるコンピューターが24時間稼働していて、
リクエストが来るたびに対応するHTMLファイルを返す。
「<html><body><h1>About</h1><p>...</p></body></html> をどうぞ」
4. ブラウザがHTMLを解釈して画面に描画する
テキスト、画像、リンクなどが表示される
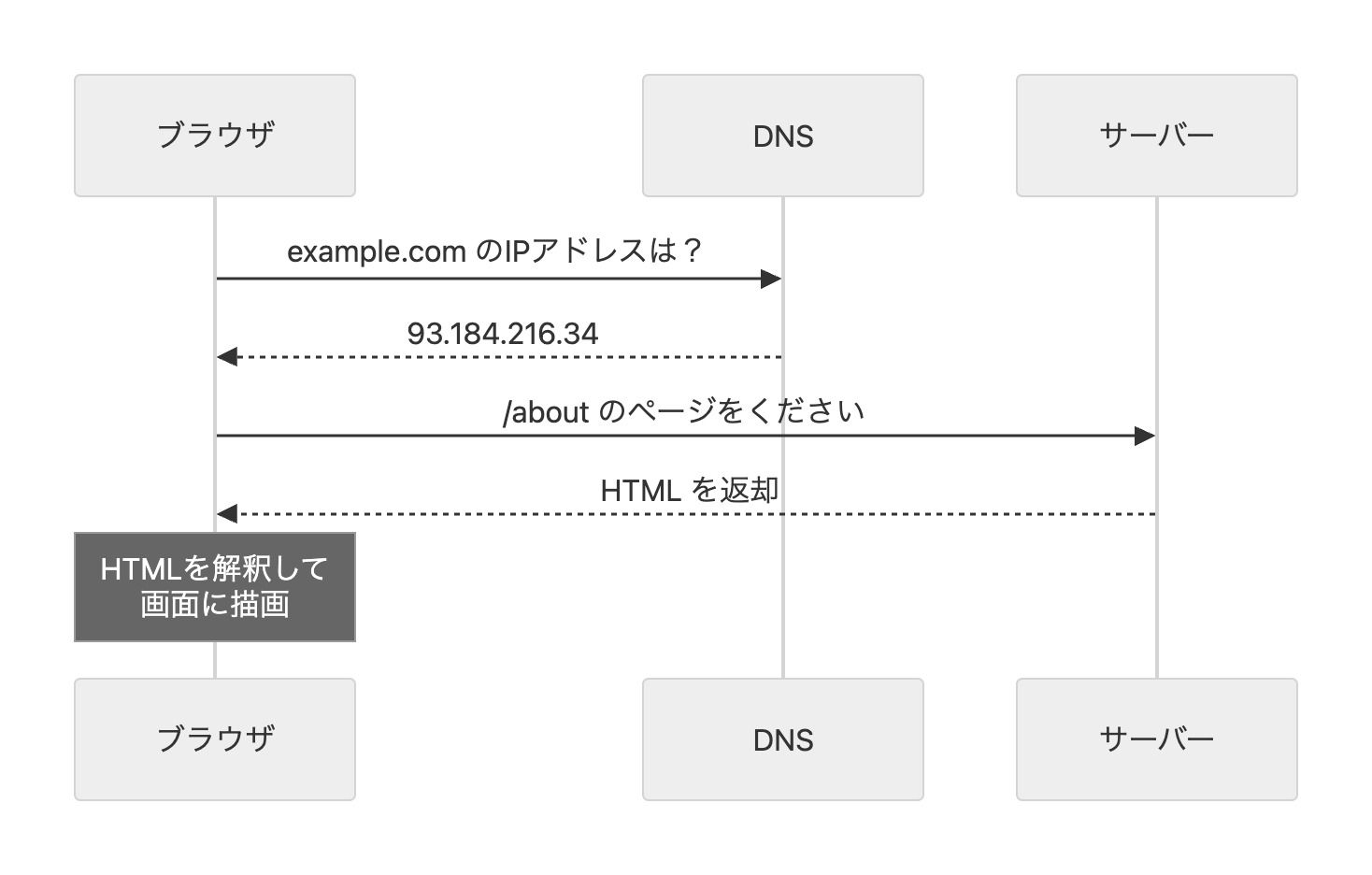
つまりWebとは、あなたのブラウザ(クライアント)が、世界のどこかにあるコンピューター(サーバー)にファイルを要求し、受け取ったHTMLを表示する仕組みだ。この基本構造は1990年代から変わっていない。
しかし、「サーバーが何を返すか」「クライアントが受け取ったものをどう扱うか」は、技術の発展とともに大きく変化してきた。
1990年代 サーバーが静的HTMLを返す → ブラウザがそのまま表示する
2000年代 サーバーがHTMLを返す → ブラウザ上のJavaScriptが一部を書き換える(Ajax)
2010年代 サーバーがJSONデータを返す → ブラウザ上のJavaScriptがUIを丸ごと構築する(SPA)
2020年代 サーバーがUIの設計図を返す → ブラウザが最小限のJSで組み立てる(RSC)
サーバーがHTML断片を返す → ブラウザが該当箇所だけ差し替える(htmx/Hotwire)
この記事は、このアーキテクチャの変遷を「なぜそう変わったのか」という必然性とともに辿るものだ。
Web黎明期 — 「文書を読む」ためのプラットフォーム
1990年代前半のWebは、研究者が論文やドキュメントを共有するための仕組みだった。ブラウザは「HTMLで書かれた文書を表示する」だけの道具で、ユーザーにできることはリンクをクリックして別のページに飛ぶことだけだった。ページの見た目を変えたければ、サーバーにリクエストを送り、新しいHTMLを丸ごと受け取って、ページ全体を読み込み直す。この「クリック → 画面が真っ白になる → 新しいページが表示される」というサイクルがWebの基本動作だった。
1995年 — JavaScript誕生
Netscape社のBrendan Eichが、わずか10日間でJavaScriptを設計した。当初の用途は「ちょっとした動き」をWebページに加えること——フォームの入力チェック(送信前に「メールアドレスの形式が正しいか」を確認する等)、マウスオーバーで画像を変える、アラートダイアログを出す、といった程度だった。
この時点のJavaScriptは、あくまでHTMLという「文書」に添える補助的なスクリプトに過ぎなかった。
1999〜2005年 — Ajaxの登場とWebの転換
1999年、MicrosoftがInternet Explorer 5で XMLHttpRequest というAPIを導入する。これは地味だが革命的な機能だった。
それまでのWebでは、サーバーから新しい情報を得るには必ず「ページ全体を再読み込み」する必要があった。XMLHttpRequestは、ページを再読み込みせずに、裏側でサーバーと通信してデータだけを受け取ることを可能にした。
// XMLHttpRequest(Ajax)の基本的な仕組み
var xhr = new XMLHttpRequest();
xhr.open("GET", "/api/notifications"); // サーバーへのリクエストを準備
xhr.onreadystatechange = function () {
// レスポンスが返ってきたら実行する関数を登録
if (xhr.readyState === 4 && xhr.status === 200) { // 4=通信完了, 200=成功
var data = JSON.parse(xhr.responseText);
// ← ここで受け取ったデータを使ってDOMを更新する
// ページ全体の再読み込みは起きない!
}
};
xhr.send(); // リクエストを送信
この技術が真価を発揮したのは2004〜2005年だ。
- 2004年: Gmail公開 — ページ遷移なしでメールの閲覧・送信・検索ができる。当時のWebメール(Hotmail等)がページ遷移だらけだったのと比べて、まるでデスクトップアプリのような操作感だった
- 2005年: Google Maps公開 — 地図をマウスでドラッグしてスクロールできる。スクロールするたびに、裏側でサーバーから地図タイルを取得して画面を書き換えていた。これは当時のWeb体験として衝撃的だった
同年、Jesse James Garrettがこの技術を 「Ajax」(Asynchronous JavaScript and XML) と命名した。「非同期JavaScriptとXML」——ページを再読み込みせず(非同期に)、JavaScriptでサーバーと通信してデータ(当時はXML形式が多かった。今ではJSONが主流)を受け取り、画面の一部だけを書き換える技術の総称だ。
これをきっかけに Web 2.0 と呼ばれるムーブメントが起きた。Webが「読むもの」から「使うもの」へ、文書プラットフォームからアプリケーションプラットフォームへと変貌し始めた瞬間だ。
コラム: Flashという「もう一つの道」
Ajaxが登場する以前から、動的でリッチなWeb体験を実現する技術がもう一つ存在していた。Adobe Flash(旧Macromedia Flash)だ。
Flashのアプローチは、JavaScriptとは根本的に異なっていた。JavaScriptが「HTMLの中に埋め込まれたスクリプト」としてブラウザの機能を拡張するのに対し、Flashはブラウザの中にプラグイン(追加ソフトウェア)として別の実行環境を丸ごと載せるというアプローチだった。
JavaScriptのアプローチ:
HTML + CSS + JavaScript → ブラウザが直接解釈・実行
Webの標準技術の上に構築する
Flashのアプローチ:
Flashプラグイン(Flash Player)をブラウザにインストール
→ HTMLの中に <object> タグで「Flashの再生領域」を埋め込む
→ その領域内ではFlash独自の世界が動く
→ ActionScript(Flash専用のプログラミング言語)で開発
Webの標準とは別の独自プラットフォーム上に構築する
Flash Player内の世界では、ベクターグラフィックス、アニメーション、音声・動画再生、リッチなUIコンポーネント——当時のHTML/CSS/JavaScriptでは到底実現できなかった表現が可能だった。2000年代前半、Flashで作られた全画面アニメーションのWebサイトや、Flashゲーム、動画プレイヤー(YouTube初期もFlash Playerを使用していた)は大流行した。
私の父はもう50になるが、彼は大学生の時にFlashを使ってwebエンジニアをしていた。
しかしFlashは、いくつかの構造的な問題を抱えていた。
- プラグイン依存: Flash Playerをインストールしていないブラウザでは一切動かない。検索エンジンのクローラーもFlashの中身を読めないため、SEOに不利だった
- セキュリティ脆弱性: Flash Playerに深刻なセキュリティホールが繰り返し発見された
- モバイル非対応: 2010年にAppleのSteve Jobsが「iOSデバイス(iPhone・iPad等)でFlashをサポートしない」と公開書簡で宣言。バッテリー消費、パフォーマンス、セキュリティを理由に挙げた。スマートフォンの急速な普及の中で、これが決定打となった
- クローズドな技術: Adobeという一企業が規格を握る独占的なプラットフォームであり、Web標準(オープンな仕様)の対極にあった
2010年代に入ると、HTML5の登場により、Flashが担っていた役割の多く——動画再生(<video> タグ)、アニメーション(CSS Animations / Canvas API)、リッチなグラフィックス(WebGL)——がブラウザの標準機能としてカバーされるようになった。2020年末、Adobe Flash Playerは正式にサポートを終了し、Flashという潮流は完全に途絶えた。
「ブラウザの外にプラグインとして独自プラットフォームを載せる」というアプローチは、最終的にWeb標準に敗れたということだ。現代のフロントエンド技術(React, Vue, Svelte等)は全て、HTML/CSS/JavaScriptというWeb標準の上に構築されている。
ただし興味深いことに、「Web標準であれば勝てる」とも限らない。第5章で触れるWeb Componentsは、W3Cが策定した正真正銘のWeb標準でありながら、ReactやVueほどには普及しなかった。Flashは「標準でなかったから」敗れ、Web Componentsは「標準であっても」苦戦した。技術の普及には、標準かどうかだけでなく、開発者が本当に必要としている問いを解決しているかが重要だということだ。
2006年〜 — jQuery以降の世界
2006年: jQuery公開 — jQueryはDOM操作の簡略化およびAjaxの実装を劇的に簡単にした。
// 生のXMLHttpRequest(10行以上のコード)が、jQueryではこれだけになる
$.get("/api/notifications", function (data) {
$("#notification-list").html(data);
});
以降に登場するフレームワークやライブラリ(Backbone.js、Angular.js等)も、Ajax通信を簡単に行うAPIを標準で備えた状態で登場してくる。「サーバーと非同期通信してUIを部分更新する」ことは、もはやWebアプリの前提条件になっていた。
年表まとめ(各用語は本文で詳しく扱う):
1995 JavaScript誕生 — 「フォームの入力チェック」程度の用途
1999 XMLHttpRequest登場 — ページ再読み込みなしのサーバー通信が可能に
2004 Gmail公開 — Webアプリケーションという概念が現実に
2005 「Ajax」命名、Google Maps公開 — Web 2.0ブーム
2006 jQuery公開 — DOM操作とAjaxを劇的に簡略化
2010 Backbone.js, AngularJS 登場 — クライアントサイドMVCフレームワーク、SPAの本格化
2013 React公開 — 宣言的UI、仮想DOM、コンポーネントモデル
2015 ES2015(ES6) — JavaScript言語自体の大幅な近代化(let/const, Promise, モジュール等)
2016 Next.js登場 — React SSRをフレームワークとして実用化
2020〜 RSC / htmx / Hotwire — ポストSPA時代の模索
以上がフロントエンド技術の大きな流れだ。ここからは各時代を掘り下げていく。
1. バニラJS時代 — Web標準だけでUIを作るということ
Ajaxの登場によって、JavaScriptの役割は「ちょっとした動き」から「画面の動的な書き換え」へと拡大した。しかしそもそも、なぜJavaScriptからHTMLを操作する必要があるのだろうか。
動的なWebページとDOM操作の関係
HTMLとCSSだけで作られた「静的な」Webページは、サーバーから送られてきたそのままの姿で表示される。ユーザーがクリックしてもテキストを入力しても、ページの見た目は変わらない(リンクをクリックすれば別のページに飛ぶが、それは画面の書き換えではなく新しいページの読み込みだ)。
しかし現実のWebには「動的な」振る舞いが求められる。
- タブをクリックしたら、表示する内容が切り替わる
- 「もっと見る」を押したら、隠れていたテキストが表示される
- フォームに入力したら、リアルタイムでエラーメッセージが出る
- 商品をカートに入れたら、ヘッダーのカート個数が増える
こうした動きはすべて、JavaScriptがHTMLやCSSを書き換えることで実現されている。タブの切り替えは、ある <div> を display: none(非表示)にして別の <div> を display: block(表示)にする操作だ。カートの個数更新は、ある要素の textContent を "3" から "4" に変える操作だ。
つまり、動的なWebページを作るためには「HTMLの中から特定の要素を見つけ出し、その要素を変更する」という作業が不可欠になる。これがDOM(Document Object Model — HTMLの各要素をJavaScriptから操作するためのAPI)操作だ。
DOM操作のプリミティブさ
では、その書き換えを実現するためのDOM操作は実際にはどんなコードになるのか。以下を一行ずつ追いかけてみてほしい。
// 2000年代初頭のバニラJS — Todoリストに1つのアイテムを追加するコード
// まず、HTMLの中から id="todo-list" を持つ要素(<ul>など)を探して取得する
var list = document.getElementById("todo-list");
// 新しい <li> 要素をメモリ上に作る(この時点ではまだ画面には表示されない)
var item = document.createElement("li");
// 作った <li> にCSSクラスを設定する
item.className = "todo-item";
// テキストを設定する
item.textContent = "Buy milk";
// 削除ボタンも同じように一から作る
var deleteBtn = document.createElement("button");
deleteBtn.textContent = "Delete";
// ボタンがクリックされた時に実行する処理を登録する
deleteBtn.onclick = function () {
// 親要素(list)から、この <li> を取り除く
list.removeChild(item);
};
// ボタンを <li> の中に入れる
item.appendChild(deleteBtn);
// 最後に、完成した <li> をリストに追加する — ここで初めて画面に表示される
list.appendChild(item);
たった1つのTodoアイテムを追加するだけでこのコード量だ。やっていることは単純で、「要素を作る → 中身を設定する → 親要素にくっつける」の繰り返しに過ぎない。だが、この手作業をUIのあらゆる部分に対して行わなければならなかった。
DOM検索APIの不足
この「要素を見つけ出す」という最初のステップからして、当時のAPIは不便だった。
// IDで要素を探す — 1つだけ見つかる
document.getElementById("main-title");
// タグ名で探す — 全ての <li> が返ってくる
document.getElementsByTagName("li");
// クラス名で探す — 全ての .active が返ってくる
document.getElementsByClassName("active");
たとえば「todo-list の中にある、completed クラスがついた li 要素だけ」を探したい場合、CSSでなら .todo-list li.completed と一発で書ける。しかし当時のJavaScriptでは、まずリストを取得し、その中の li を全部取り出し、一つずつクラス名を調べる......というループを書かなければならなかった。CSSセレクタで検索できる querySelector が標準化されたのは2009年頃のことだ。
コールバック地獄
もう一つの大きな問題が、非同期処理(結果がすぐに返ってこない処理)の扱いだった。
たとえば、Ajaxでデータを取得する場面を考えよう。サーバーへのリクエストはネットワークを経由するため、結果が返ってくるまで時間がかかる。その間、ページ全体がフリーズしてしまっては困るので、JavaScriptは「結果が返ってきたら、この関数を呼んで教えてね。その間他の処理進めておくから」という形でコールバック関数を渡す。
// 「ユーザー情報を取得し、そのユーザーの投稿一覧を取得し、最新投稿の詳細を取得する」
// まずユーザー情報を取得する
getUser(userId, function (user) {
// ↑ ユーザー情報が返ってきたらこの関数が呼ばれる
// 次に、そのユーザーの投稿一覧を取得する
getPosts(user.id, function (posts) {
// ↑ 投稿一覧が返ってきたらこの関数が呼ばれる
// さらに、最新投稿の詳細を取得する
getPostDetail(posts[0].id, function (detail) {
// ↑ 詳細が返ってきたらこの関数が呼ばれる
// ここでようやく全データが揃い、画面を更新する
displayPostDetail(detail);
});
});
});
コールバック関数とは、「ある処理が終わったら呼び出してもらう関数」のことだ。上の例では3段のコールバックが入れ子になっている。「ユーザーを取得してから → 投稿一覧を取得してから → 詳細を取得する」という順序の依存関係があるため、それぞれの「完了後」の処理を前のコールバックの中に書くしかない。
これが5段、10段と深くなると、コードは右に右にインデントが深まり、読み解くのが極めて困難になる。これが「コールバック地獄」と呼ばれた状態だ。
(現代のJavaScriptでは async/await という仕組みがあり、同じ処理を平坦に書ける。しかし当時はそれがなかった。)
状態追跡の困難さ
こうしたDOM操作コードが膨らんでくると、「今、画面はどういう状態にあるか」を追跡することが極めて困難になった。この辛さを擬似的に体験してみよう。
以下のコードを上から順に読んで、最後に画面がどうなっているかを頭の中で追いかけてみてほしい。
// 初期状態: ボタンA, ボタンB, メッセージ欄がある
document.getElementById("msg").textContent = "ようこそ";
document.getElementById("btnA").style.display = "block";
document.getElementById("btnB").style.display = "none";
// ボタンAをクリックしたら...
document.getElementById("btnA").onclick = function () {
document.getElementById("msg").textContent = "Aが押されました";
document.getElementById("btnA").style.display = "none";
document.getElementById("btnB").style.display = "block";
document.getElementById("msg").style.color = "blue";
};
// ボタンBをクリックしたら...
document.getElementById("btnB").onclick = function () {
document.getElementById("msg").textContent = "Bが押されました";
document.getElementById("btnB").style.display = "none";
document.getElementById("btnA").style.display = "block";
document.getElementById("msg").style.color = "red";
};
この程度ならまだ追える。では質問だ。
「ボタンAを押して、次にボタンBを押して、もう一度ボタンAを押した後の画面はどうなっているか?」
これに回答するためには、頭の中で3回分の状態変更をシミュレーションする必要がある。
これがたった20行のコードでの話だ。実際のアプリケーションでは、何十個もの要素が、何百行ものイベントハンドラから操作される。しかもイベントはユーザーの操作順によって発火タイミングが変わる。「ボタンAの処理中に、タイマーで登録した別の処理が割り込む」といったことも起きる。
こうなると、「今この要素は表示されているのか? テキストは何になっているのか? どのクラスがついているのか?」を正確に追跡することは、人間の認知能力を超える。これが「DOMの状態が追跡不能になる」という問題の正体だ。
実際、バニラJSでフレームワークの役割を果たせるような標準APIはほとんど進化しなかったという指摘もある。もちろん、かつてはJavaScriptなしでもWebは作れた。だが、ユーザーが期待するUI体験は年々高度になっていき、バニラJSだけでは対応しきれなくなっていったのだ。
2. jQuery時代 — 便利な道具が構造を与えてくれなかった話
jQueryが解決したこと
2006年にJohn Resigが公開したjQueryは、バニラJS時代の主要な苦痛を解消した。
// バニラJS — 長くて、ブラウザによっては動かないかもしれない
document.getElementById("myElement").style.display = "none";
// jQuery — 圧倒的に短く、どのブラウザでも動く
$("#myElement").hide();
jQueryの $() は万能のDOM検索関数だ。CSSセレクタをそのまま渡せるので、前章で触れた「querySelector がなかった問題」を一気に解決した。
- ブラウザ間の差異を吸収:
$()一つでどのブラウザでも動く - CSSセレクタでDOM検索:
$('.todo-item.completed')のように、CSSと同じ感覚で要素を探せる - メソッドチェーン: 一つの操作結果に対して次の操作を
.で連ねて書ける
// メソッドチェーン: 「リストを探す → 中のliを全部取得 → activeクラスを付ける → フェードインする」
// これを一行で書ける
$("#list").find("li").addClass("active").fadeIn();
// もしバニラJSで書くと...
var list = document.getElementById("list");
var items = list.getElementsByTagName("li");
for (var i = 0; i < items.length; i++) {
items[i].className += " active";
// フェードインのアニメーションは自前で実装する必要がある...
}
- Ajax通信の簡素化:
$.ajax()でXMLHttpRequestの複雑さを隠蔽
jQueryは「DOMを便利に操作するツール」としては極めて優秀だった。一時期はWebサイトの約70%以上がjQueryを使用していたとされる。
jQueryが解決できなかったこと — 本質的な問題
しかしjQueryは、DOMを操作する「方法」は改善したが、DOMを操作する「構造」は提供しなかった。操作が便利になったぶん、構造なきコードが大量に書かれ、問題はむしろ深刻化した。ここに3つの根本的な問題がある。
問題1: 状態とDOMの二重管理
// jQueryでのTodoアプリ(典型的な問題コード)
var todos = []; // ← JavaScriptが管理する「データ」
$("#add-btn").click(function () {
var text = $("#input").val();
todos.push({ text: text, done: false }); // ← データを更新
// ↓ データを変えたら、DOMも手動で変えないといけない
var $li = $("<li>").text(text);
var $checkbox = $('<input type="checkbox">').change(function () {
// ↓ DOMの操作(チェックボックス)が起きたら、データも手動で変えないといけない
var index = $(this).parent().index();
todos[index].done = $(this).is(":checked");
$(this).parent().toggleClass("completed");
updateCount(); // ← カウント表示も手動で更新
});
$li.prepend($checkbox);
$("#todo-list").append($li); // ← DOMに追加
updateCount(); // ← カウント表示も手動で更新
});
ここで起きている二重管理を整理しよう。

データ(JavaScript側) 画面(DOM側)
───────────────── ─────────────────
todos = [ <ul id="todo-list">
{text:"Buy milk", <li>Buy milk ☐</li>
done: false} </ul>
]
→ データを変えたら、DOMも手動で合わせる
← DOMが変わったら、データも手動で合わせる
← さらにカウント表示も手動で合わせる
どちらか一方の更新を忘れると、データと画面がズレる
この「データの真実」と「画面の真実」が二箇所に存在してしまうことが問題の核心だ。todoを1つ追加するだけで、todos 配列の更新、<li> の作成、カウントの更新、チェック時のデータ更新、チェック時のクラス切り替え......と複数の箇所を同期しなければならない。一箇所でも忘れると、データと画面がズレる。そしてアプリケーションが大きくなるほど、この同期は複雑になり、確実に破綻する。
問題2: DOMの状態が追跡不能になる
jQueryのコードは「DOMに対する操作の命令列」だ。前章の状態追跡の例をjQueryで拡大してみよう。
// 通知パネルのjQueryコード(実際のプロジェクトから簡略化したもの)
$("#notification-bell").click(function () {
$("#panel").slideToggle(); // パネルの表示/非表示を切り替え
$(this).toggleClass("active"); // ベルのスタイルを切り替え
if ($("#panel").is(":visible")) {
$.get("/notifications", function (html) {
$("#panel").html(html); // 通知を読み込んで表示
$("#badge").text(""); // バッジを消す
$("#badge").removeClass("has-new"); // バッジのスタイルも消す
});
}
});
$("#panel").on("click", ".mark-read", function () {
$(this).closest(".notification").fadeOut(); // 通知を一つ消す
var count = $("#panel .notification:visible").length;
if (count === 0) {
$("#panel").append('<p class="empty">通知はありません</p>');
}
});
// さらに別のファイルに...
setInterval(function () {
$.get("/notifications/count", function (data) {
if (data.count > 0) {
$("#badge").text(data.count).addClass("has-new");
}
});
}, 30000); // 30秒ごとに新着確認
このコードの問題は、3つのイベントハンドラが #panel #badge といった同じDOM要素を別々の場所から操作していることだ。しかも slideToggle の完了タイミングとAjax通信の完了タイミングは保証されていない。前章で体験したように、こうした操作の積み重ねは人間には追跡不能になる。
バニラJS時代の課題は解決されなかったわけだ。実際、当時のjQueryで作り込んだページは、長く操作していると表示が壊れてリロードが必要になることが珍しくなかった(これはのちにBackbone.jsなどの初期SPAフレームワークが登場しても、DOM更新がjQuery手書きである限り同様だった)。
問題3: 属人的で読めないコード
「他人が書いた生DOM操作は読めないもの」という認識は、jQuery時代の開発者にとっては常識だった。Reactが登場して初めて、他人が書いたコンポーネントが読解できるようになったと言われるほどだ。
なぜ読めないのか。同じ「タブ切り替えUI」を2人の開発者が書くと、こうなることがあった。
// 開発者Aのアプローチ: CSSクラスで制御
$(".tab").click(function () {
$(".tab").removeClass("active");
$(this).addClass("active");
$(".panel").hide();
$("#" + $(this).data("panel")).show();
});
// 開発者Bのアプローチ: data属性とインデックスで制御
$(".tab-header").on("click", "li", function () {
var idx = $(this).index();
$(this).siblings().css("font-weight", "normal");
$(this).css("font-weight", "bold");
$(".tab-body").children().eq(idx).show().siblings().hide();
});
どちらも「タブ切り替え」を実現しているが、アプローチが全く違う。HTML構造の前提も違う。変数名や制御の仕方も違う。10人いれば10通りの書き方になる。これはスキルの問題ではなく、もっと根本的な問題だ。
手続き的プログラミングとUIの相性の悪さ
ここまで見てきたjQueryのコードはすべて手続き的(imperative)なプログラミングスタイルで書かれている。手続き的プログラミングとは、「この要素を取得して、このクラスを外して、次にこのクラスを付けて、あのパネルを隠して、このパネルを表示する」——というように、処理の手順を一つずつ命令として記述するスタイルだ。プログラミングの世界では最も基本的で広く使われているアプローチであり、サーバーサイドの開発(Go, Java, Python等)では今でも主流のスタイルである。
しかし、UIの構築においては、手続き的アプローチには構造的な問題があった。手続き的コードは「現在の状態からどう変化させるか」を記述する。つまり、今の画面がどうなっているかを把握した上で、そこからの差分を手順として書く必要がある。タブが1つならまだいい。だが操作が重なり、非同期処理が絡み、状態の組み合わせが増えると、「今の画面がどうなっているか」の把握自体が不可能になっていく。これが前章で見た「DOMの状態追跡が不可能」という問題の正体だ。
これに対して、もう一つのアプローチがある。宣言的(declarative)プログラミングだ。手順を書くのではなく、「このデータのとき、UIはこう見えるべきだ」という結果の状態を記述するスタイルである。SQLが身近な例だ——「どのデータが欲しいか」を宣言すれば、データベースが取得方法を決める。UIにおいても同じ発想で、「このデータのときの画面はこうだ」と宣言できれば、手順を一つずつ書く必要はなくなる。
jQuery時代の開発者たちの間にも、この「宣言的にUIを書きたい」というニーズは沸々と湧き上がっていた。手続き的DOM操作の限界は、経験を積むほど痛感するものだったからだ。
テンプレートエンジンという部分的な解
実際、一部の開発者はクライアントサイドのテンプレートエンジン(doT, Mustache, Handlebars等)を使い、「データからHTMLを一括生成してinnerHTMLで差し込む」という宣言的なアプローチを試みていた。
// doTテンプレートエンジンのアプローチ
// テンプレート(HTMLの雛形)を定義して、データを流し込むとHTMLが出来上がる
var template = doT.template(
"<ul>{{~it:item}}<li>{{=item.text}}</li>{{~}}</ul>",
);
var html = template(todos); // データからHTML文字列を生成
$("#todo-list").html(html); // 既存の中身を丸ごと置き換え
これは「データ → HTML」という一方向の変換であり、宣言的と言える。しかしこのアプローチには致命的な問題があった。データが変わるたびにDOM全体を作り直すため、パフォーマンスが悪く、フォーカス状態やスクロール位置が失われ、アニメーションも途切れる。たとえば入力中のテキストフィールドが消えて再生成されてしまう。
こうしたテンプレートエンジンの利用は少数派で、多くの開発者はjQueryを使い続けていた。「宣言的UI」という概念自体はテンプレートエンジンの時代から存在していたが、Reactの登場で爆発的に認知されることになる。
「宣言的に書きたい(テンプレート)」と「効率的に更新したい(差分更新)」の両立 — これこそがReactが後に解決する問いだった。
3. サーバーだけでは完結しなくなった理由
サーバーサイドテンプレートの構造
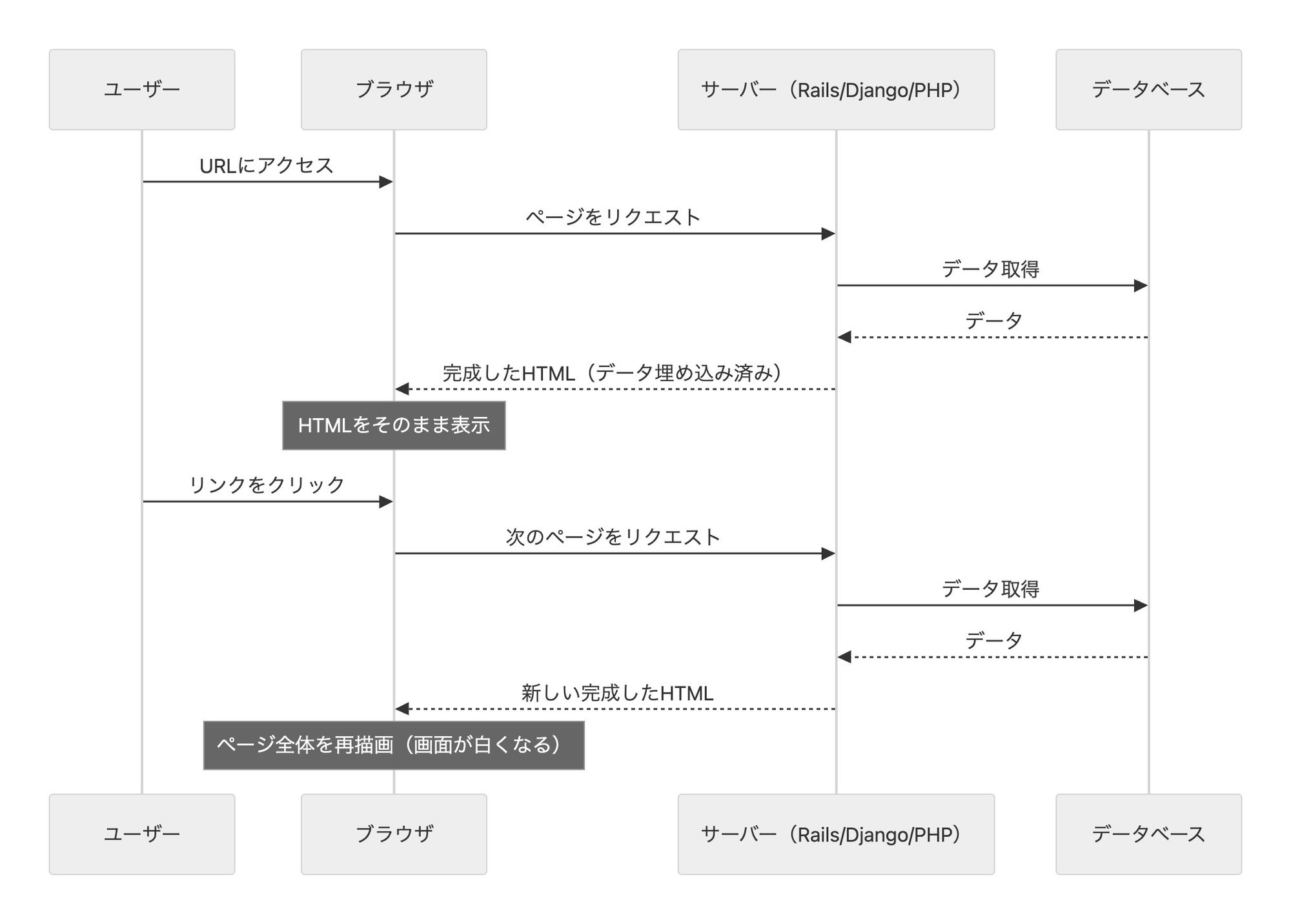
前章でテンプレートエンジンに少し触れたが、サーバーサイドでは、PHP/Rails/Django等のテンプレートエンジンが広く使われていた。
<!-- Rails ERB テンプレート -->
<!-- Rubyが分からなくても雰囲気で読める: -->
<ul>
<% @todos.each do |todo| %> <!-- @todosの各要素について繰り返す -->
<li class="<%= 'completed' if todo.done? %>"> <!-- 完了済みなら 'completed' クラスを付ける -->
<%= todo.text %> <!-- todoのテキストを出力する -->
</li>
<% end %>
</ul>
これは「データ(@todos)が与えられたら、UIはこうなるべき」という宣言だ。「データ → HTML」の一方向の変換であり、jQueryのように「どのDOM要素をどう操作するか」という手順を書く必要がない。PHP/Railsなどサーバーサイド出身の開発者からすれば、ずっと宣言的スタイルでやってきたことになる。
なぜサーバーだけでは完結しなくなったか
このサーバーサイドテンプレートの仕組みはシンプルで強力だった。しかし根本的な制約がある。テンプレートが実行されるのはサーバー上であり、ユーザーがブラウザで何か操作するたびにサーバーと通信が必要になるということだ。
HTTP(Webの通信プロトコル)は設計上ステートレス(状態を持たない)なプロトコルだ。ステートレスとはどういうことか。レストランに例えると、ウェイターが注文を取りに来るたびに「こちらのテーブルは初めてですか? 何名様ですか?」と聞かれるようなものだ。前回のやり取りを一切覚えていない。Webサーバーも同じで、リクエストが来るたびに「あなたは誰? 何がほしい?」を一から処理する。
つまりサーバーは「今ドロップダウンが開いているか」「ユーザーが何文字入力したか」といった画面の状態を覚えていない。リクエストが来たら、データベースの状態を元にHTMLを返す——ただそれだけの関数だ。画面の細かい状態はサーバーの関心事ではない。
2000年代前半はこれで十分だった。しかしUI/UXの要求が高度になるにつれ、サーバーに都度問い合わせることが許容できない場面が増えていった。
2000年代前半(サーバーで完結できた時代):
・フォーム送信 → サーバーで処理 → ページ全体リロード
・これで十分だった
2010年代(サーバーだけでは辛くなった時代):
・ドロップダウンの開閉(サーバーに聞く? → 遅すぎる)
・フォームのリアルタイムバリデーション(毎キー入力でサーバー? → 遅すぎる)
・ドラッグ&ドロップの並べ替え(マウス移動ごとにサーバー? → 不可能)
・オートコンプリート(入力ごとにサーバーは可能だが遅い)
・無限スクロール、ページ内遷移、アニメーション...
こうした「即時的なUI操作」は、ネットワーク遅延(一般的に数十〜数百ミリ秒)を挟むサーバー側では処理できない。ドロップダウンを開くのに100ミリ秒待たされたら、ユーザーは違和感を覚える。ドラッグ操作中にネットワーク通信を挟むのは論外だ。
こうしてクライアント側(ブラウザ)のJavaScriptでUIの状態を管理することが不可避になった。サーバーはステートレスで画面の状態を覚えていない。ならば「今ドロップダウンが開いているか」「入力中のテキストは何か」といったUI状態は、ブラウザ側のJavaScriptが持つしかない。
宣言的UIの「再発明」
先述した通り、サーバーサイドは「宣言的」だった。サーバーサイドの構造を整理すると、こうなる。
サーバーサイドの宣言的UI:
データベース(状態) → サーバー(関数) → HTML(UI)
UI = f(state) ← Reactと同じ構造
「データベースは広義の状態管理であり、Webサーバーとは、HTTPリクエストとデータベース内の状態からHTMLを描画する関数である」——つまり「宣言的UI」を突き詰めると、「UIとは、状態を受け取ってHTMLを返す関数である(UI = f(state))」という考え方に行き着く。そしてこの構造を見れば、その概念はサーバーサイドでは最初からそうだったことが分かる。しかし人類がこの構造を自覚的に認識し、クライアントサイドに移植するまでに20年を要した。それがReactの UI = f(state) である。
そしてこの宣言的UIの意義は、10年経った今でもまだ十分に理解されていないようだ。
第2部: Reactという発明
4. Reactが解決した本質的な問題
Reactの前夜 — MVC・双方向バインディングの挫折
当時の開発者たちは、データバインディングを欲していた。データバインディングとは、JavaScriptのデータとUIを自動的に連携させる仕組みのことだ。たとえば user.name が "Alice" から "Bob" に変わったら、画面上の名前表示も自動的に "Bob" に変わってほしい。jQuery時代はこれを手動でやっていた。
しかしテンプレートエンジンだけではデータバインディングは実現できない。なぜなら、テンプレートエンジンは本質的に「呼ばれたらデータをHTMLに変換する」だけの関数だからだ。データが変わったことを検知する仕組みも、変わったときに自動で再実行される仕組みも持っていない。「いつ・何が変わったか」を監視して再描画をトリガーする仕組みは、テンプレートの外側に別途作る必要がある。
ここで振り返ると、前章で見たように、即時的なUI操作(ドロップダウンの開閉、リアルタイムバリデーション等)のためにUIの生成・更新の責任がサーバーからブラウザ側のJavaScriptに移りつつあった。サーバーが完成したHTMLを返す時代には、UIの構築はサーバーの仕事だった。しかしクライアントサイドでUIを組み立てるようになると、そのコードを整理する方法が必要になる。
そこで当時の開発者たちが手を伸ばしたのが、サーバー上で成功していたMVC(Model-View-Controller)というアーキテクチャだった。サーバーでうまくいっていた設計パターンを、ブラウザのJavaScript上に複製しようとしたのだ。
MVCとは、アプリケーションを3つの役割に分離する設計パターンだ。
- Model(モデル): データと、データを変更するロジック(例: todoリスト、ユーザー情報)
- View(ビュー): 画面の見た目(例: HTMLテンプレート)
- Controller(コントローラー): ユーザーの操作を受け取り、ModelとViewを仲介する(例: 「追加ボタンが押されたらModelにtodoを追加し、Viewを更新する」)
サーバー上では、この構造はうまく機能していた。MVCの3つの役割がすべてサーバー上で完結していたからだ。Modelはデータベースのレコード(永続的なデータ)、Viewは前章で見たようなテンプレートエンジン(ERB, PHP等)で生成されるHTML、Controllerはリクエストを受け取るサーバーのコード。リクエストが来るたびにControllerが動き、Modelからデータを取得し、Viewでページ全体をレンダリングしてブラウザに返す。重要なのは、Viewはリクエストごとに毎回作り直される使い捨てだということだ。作って返したらそれで終わり。だから状態の管理がシンプルだった。
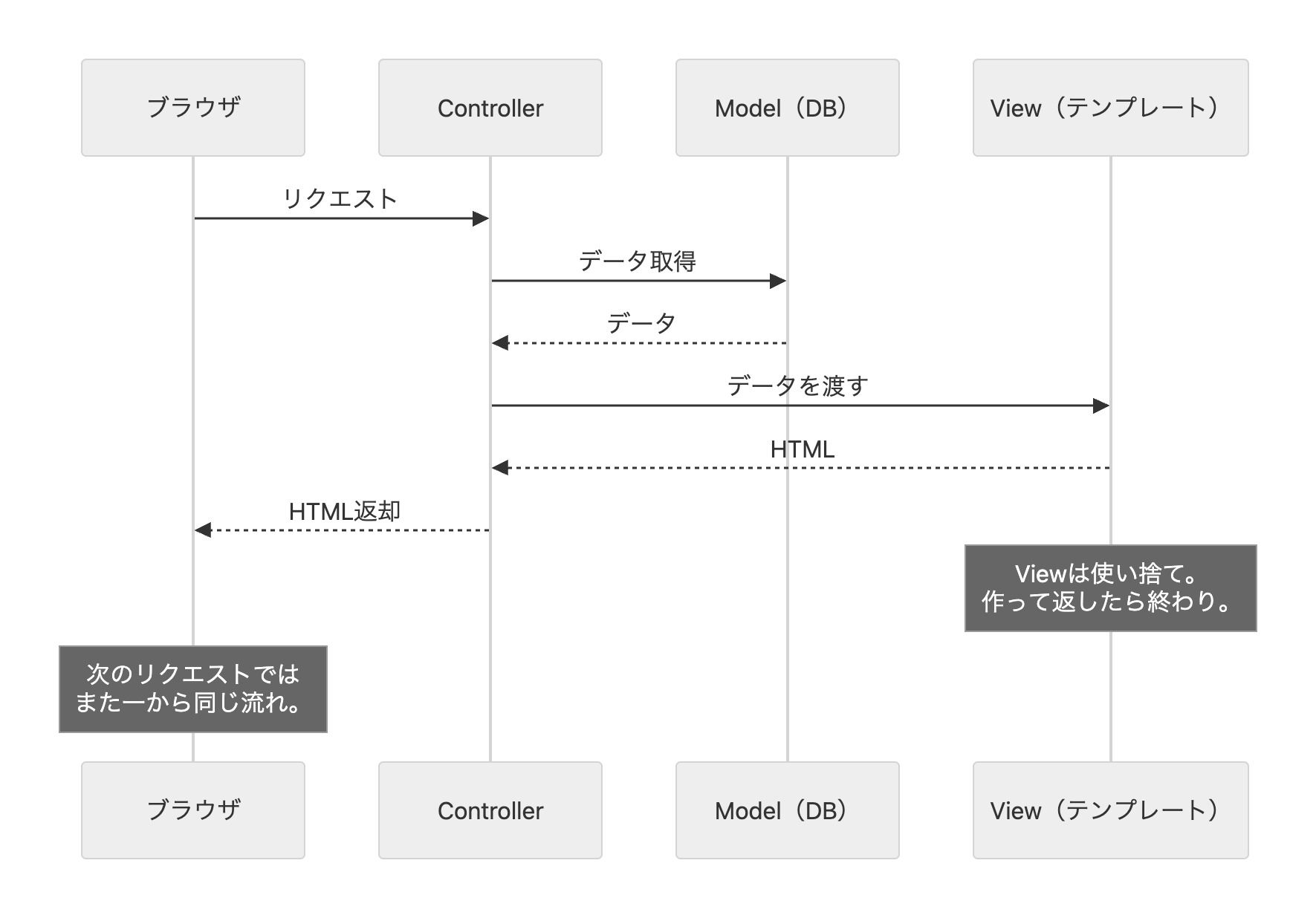
しかしこのMVCアーキテクチャをブラウザのJavaScript上に複製しようとすると、ModelとViewの意味が根本的に変わる。フロントエンドのModelはデータベースではなく、JavaScriptのメモリ上にあるUI状態だ。「ドロップダウンが開いているか」「ユーザーが入力中のテキスト」「どのタブが選択されているか」——こうした一時的で画面に紐づくデータがModelになる。そしてViewは使い捨てのHTMLではなく、画面に表示され続けるDOMだ。ユーザーが操作するたびにリアルタイムに変わり続ける。
つまりフロントエンドでは、ページが表示されている間ずっと「Modelが変わったらViewを更新する」「Viewが変わったら(ユーザーの入力)Modelも更新する」という同期を維持し続けなければならない。サーバーサイドの「作って返して忘れる」とは根本的に異なる。
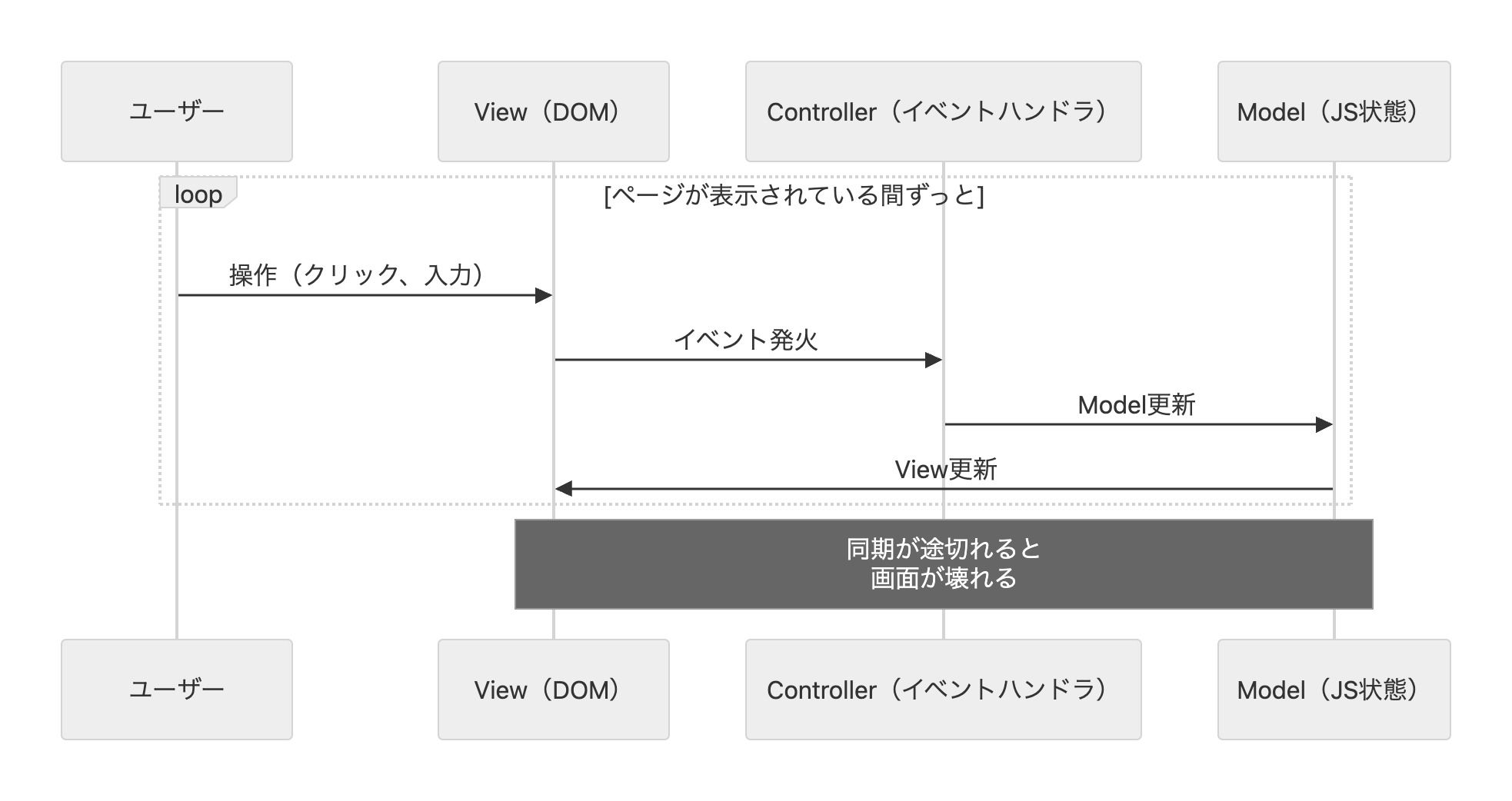
たとえばBackbone.js(2010年)はまさにフロントエンドMVCフレームワークだったが、Modelが変わったときにどのViewを更新すべきかを開発者が手動で管理する必要があり、アプリが大きくなるとModelとViewの依存関係が複雑に絡み合って追跡不能になった。AngularJS(2010年)は双方向データバインディングで自動同期を試みた。双方向データバインディングとは、「データが変わったら画面が自動更新される」だけでなく、「画面上のinputにユーザーが文字を打ち込んだら、データも自動的に変わる」という仕組みだ。
<!-- AngularJS の双方向データバインディング -->
<input ng-model="user.name" />
<p>Hello, {{user.name}}</p>
<!-- inputに打ち込むだけで user.name が変わり、<p>の表示も自動で変わる -->
一見すると理想的な仕組みに見える。しかしアプリが大きくなると、データAの変更がView Bに伝わり、View BがデータCを自動変更し、データCの変更がView Dに伝わり…という変更の連鎖が発生して、「なぜこの画面が変わったのか」の発生源が追跡不能になった。Facebookが通知バッジの数字がどうしても合わなくなるバグに悩まされたのは、まさにこの連鎖が原因だった。
つまり、「データバインディングが欲しい」→「そのためにMVCフレームワークを構築する」→「双方向バインディングの複雑さ自体が新たな問題になる」という悪循環に陥っていた。
Reactの誕生(2011〜2013年)
この悪循環の渦中にあったFacebookで、2011年、エンジニアのJordan WalkeがReactの開発を始めた。当時Facebookは、ニュースフィードや広告管理ツールなど複雑なUIの管理に苦しんでいた。Walkeは、Facebook社内で使われていたPHPのコンポーネントライブラリ「XHP」からインスピレーションを受け、同じ考え方をJavaScriptに持ち込もうとした。
2013年5月、JSConf USでReactが初めて公開された。当初、コミュニティの反応は懐疑的だった。特にJSX(JavaScript XML — JavaScriptの中にHTMLのようなタグを書ける拡張構文)は「関心の分離に反する」と批判された。当時は「HTML(構造)・CSS(見た目)・JavaScript(振る舞い)はファイルを分けるべきだ」という考え方が常識であり、JSXのようにJavaScriptの中にHTMLを書く発想は異端に見えたのだ。しかしReactは、それまでの全てのアプローチが持っていた根本的な問題を解決していた。MVCとも双方向バインディングとも異なる発想で、この問題に正面から向き合ったのだ。そのアプローチの核心が一方向データフローだ。
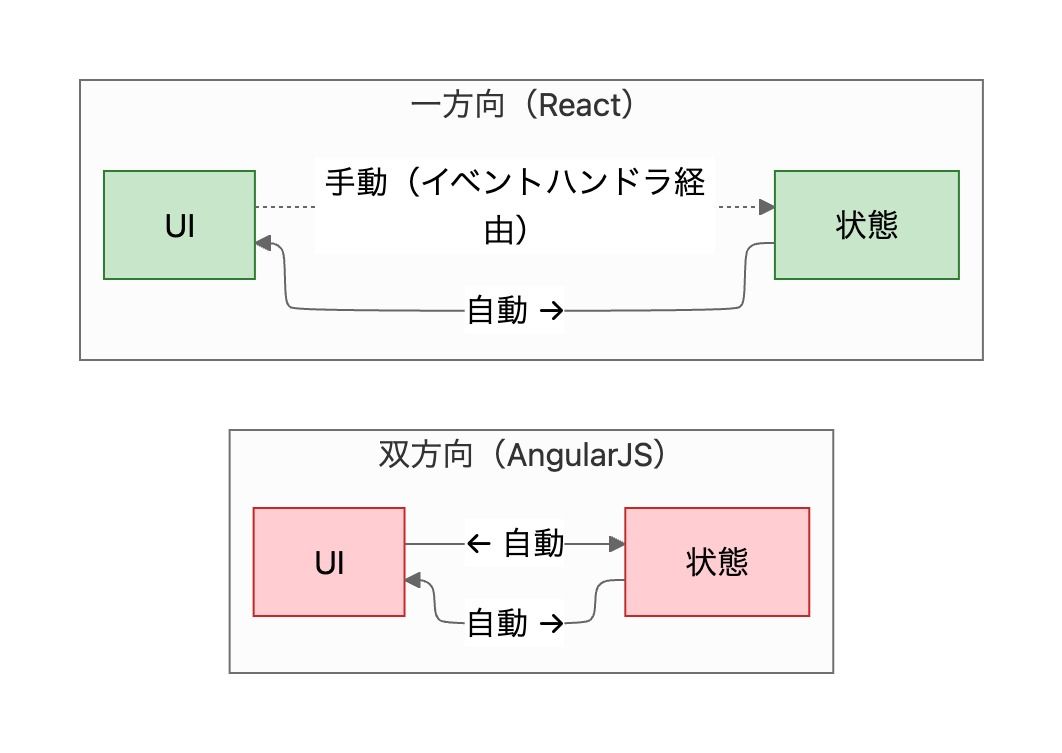
双方向(AngularJS):
状態 → UI 自動
UI → 状態 これも自動。inputに打つだけでデータが変わる
→ どこが変更の発生源か追跡不能に
一方向(React):
状態 → UI 自動。stateが変われば画面が更新される
UI → 状態 手動。開発者がonChangeでsetStateを書く
→ 状態を変えるのは常にsetStateを呼んだ箇所だけ。追跡可能
一見するとReactの方が面倒に見える。しかし「状態がどこで変わったか」が常に明確になるため、アプリが大規模になるほどこの設計が効いてくる。実際、この教訓は業界全体に浸透し、現在のAngular(2以降)も内部的には一方向データフローに再設計されている。双方向バインディングの構文は残っているが、それは一方向バインディング+イベントハンドラの糖衣構文であり、AngularJSとは根本的に異なる。
Reactが提示した3つの解
この一方向データフローの上に、Reactは3つの具体的な解を構築した。
解決1: 状態とUIの自動同期 —「UIは状態の関数」
Reactは、データとUIの同期という根本問題をこう解消した。
// React: 状態を宣言すれば、UIは自動的にそれを反映する
function TodoApp() {
// useState: 状態(ここではtodo配列)を管理する。
// todosが現在の値、setTodosが値を更新する関数。
const [todos, setTodos] = useState([]);
// ↓ ここにはDOMの操作命令が一切ない。
// 「todosの中身に応じて、UIはこうあるべき」を宣言しているだけ。
return (
<ul>
{todos.map((todo) => (
<li key={todo.id} className={todo.done ? "completed" : ""}>
{todo.text}
</li>
))}
</ul>
);
// todosが変わると、Reactが自動的にDOMを更新してくれる。
// 開発者は「どの要素を追加/削除するか」を考える必要がない。
}
数学の関数のように考えるとわかりやすい。y = 2x という関数があれば、x に 3 を入れれば y は必ず 6 になる。同じように UI = f(state) なら、state(データ)が決まれば UI(画面の見た目)は一意に決まる。
開発者は「UIがどうあるべきか」だけを宣言する。「どうやってDOMを変更するか」は考えなくていい。todos が変われば、Reactが自動的にDOMを更新する。状態の変更は常に setState(ここでは setTodos)を通じて行うため、データの流れが一方向に保たれる。
解決2: コンポーネントによる読解可能なUI
第2章で触れたように、jQuery時代は他人が書いたDOM操作コードを読み解くことが極めて困難だった。Reactのコンポーネントはこの問題を構造的に解決した。
// Reactコンポーネント: 誰が書いても構造が読める
function UserCard({ user }) {
// 入力: userオブジェクト
return (
// 出力: UIの宣言
<div className="card">
<Avatar src={user.avatar} /> {/* 別のコンポーネントを部品として使う */}
<h2>{user.name}</h2>
<p>{user.bio}</p>
</div>
);
}
// props(入力)とJSX(出力)が明確。隠れた副作用がない。
// HTMLに近い見た目なので、コードを読むだけで画面構造が想像できる。
jQuery時代は前章で見たように、同じタブUIでも人によって全く違うコードになった。Reactでは <UserCard> <Avatar> <TodoList> といった名前付きの再利用可能な部品としてUIを構成する。命名規則も構造も統一されるため、誰が書いても読める。
解決3: 差分更新による効率的な再描画
テンプレートエンジンの「全体を毎回作り直す」問題を、仮想DOM(後述)による差分検出で解決した。開発者は「毎回全体を宣言する」つもりでコードを書くが、Reactは内部で「前回と今回の差分」だけを実際のDOMに適用する。
開発者の視点:
state変更 → 全体を再宣言(毎回全部書く感覚)
「このデータなら、UIはこう」と毎回完全な形を書くだけ。
Reactの内部:
state変更 → 仮想DOM再構築 → 前回との差分検出 → 差分だけ実DOM更新
「前回と比べて変わったのはここだけ」と判定して、最小限の更新だけ行う。
これにより「宣言的に書きたい」と「効率的に更新したい」が両立した。テンプレートエンジンのように毎回全体を書き直す感覚で書けるのに、実際には変更箇所だけが更新される。jQuery時代に不可能だった、テンプレートの可読性と差分更新のパフォーマンスの両取りが実現した。
「再発明」の警告
Reactをやめると、開発者は大抵以下のような道を辿って、結果的に再発明することになる。
- 最初はバニラJSで快適に書ける(要素が少ないうちは問題ない)
- 複雑になるとDOMの状態管理が辛くなる(あれ、あの要素は今表示されてたっけ?)
- テンプレートを導入する(データからHTML生成すれば楽になるはず!)
- テンプレートの全体再構築が遅いので、差分更新を自前で実装し始める(変わった部分だけ更新しよう...)
- 再利用可能なコンポーネント的な仕組みを作り始める(ヘッダーとかサイドバーとか共通化したい...)
- 気づいたらReactの劣化版を再発明している
これはReactが「一つの意見」ではなく、UIの複雑さに対する構造的な解であることを示している。React/Next.jsが使われ続けているのは、宗教ではなく合理性による選択なのだ。
5. 仮想DOMという現実解
なぜ仮想DOMが選ばれたか
「宣言的UIが良い」ということ自体は、React以前から多くの開発者が感じていた。問題は「どうやって実現するか」だった。2013年前後、クライアントサイドで宣言的にUIを構築する方法として、複数のアプローチが模索されていた。これらはSPAに限った話ではなく、ページの一部をJavaScriptで動的に更新するあらゆる場面に関わる。
アプローチ1: テンプレート + innerHTML一括置換
最もシンプルだが、前述の通り全体再構築によるパフォーマンス劣化とUX破壊(入力中のフォーカスが消える等)が問題。
アプローチ2: morphdom等の実DOM差分比較
実DOMツリー同士を直接比較して差分を適用する方法。しかし当時は実行速度が伴わなかったとされる。実DOMは重い。ブラウザは <div> 要素一つに対して、位置、サイズ、スタイル、イベント、アクセシビリティ情報など何百ものプロパティを管理している。実DOMを読み取るだけでブラウザのレイアウト計算が誘発されるため、大規模なツリーでは遅くなる。
アプローチ3: Tagged Template Literals(Lit等)
テンプレートリテラル(JavaScriptのバッククォート ` を使った文字列テンプレート機能)を使ってHTMLを宣言的に書く方法。
// Lit(Web Componentsベースのライブラリ)の例
import { html, LitElement } from "lit";
class MyCounter extends LitElement {
static properties = { count: { type: Number } };
count = 0;
render() {
// html`...` がTagged Template Literal。
// 見た目はHTMLだが、実態はJavaScriptの文字列テンプレート。
return html`
<p>Count: ${this.count}</p>
<button @click=${() => this.count++}>+</button>
`;
}
}
JSXと似た「JavaScriptの中にHTMLを書く」アプローチだが、JSXがビルドツールで変換される独自構文なのに対し、Tagged Template LiteralsはJavaScript標準の機能をそのまま使う。ビルド不要で動くのが利点だ。しかしエディタから見ると、バッククォートの中身はただの文字列なので、LSP(Language Server Protocol — エディタの補完・エラー表示等を提供する仕組み)との連携が不十分になる。たとえば <buttton> とタイポしてもエラーが出ない、属性名の補完が効かないなど、開発体験にハンデがあった。
アプローチ4: 仮想DOM(React)
仮想DOMとは何か。具体例で見てみよう。
実DOM(ブラウザが管理する、重いオブジェクト):
<ul> ← 位置、サイズ、スクロール位置、イベントリスナー...
<li>Buy milk</li> ← 同上、何百ものプロパティ
<li>Walk dog</li> ← 同上
</ul>
仮想DOM(Reactが管理する、軽いJSオブジェクト):
{ type: 'ul', children: [
{ type: 'li', text: 'Buy milk' }, ← ただのJSオブジェクト。プロパティは数個だけ
{ type: 'li', text: 'Walk dog' }
]}
たとえるなら、建物を改築するとき、毎回建物全体を壊して建て直す(innerHTML一括置換)のではなく、新旧の設計図(仮想DOM)を見比べて「ここの壁だけ変わった」と特定し、その部分だけ工事する——というイメージだ。設計図同士の比較は紙の上の作業なので速い。実際の建物(実DOM)をいちいち計測して回る必要がない。
仮想DOMは「最も美しい解」ではなかったかもしれないが、2013年時点で利用可能な技術の中で最もバランスの取れた現実解だった。
Web Componentsはなぜ普及しなかったか
Web Components(Custom Elements, Shadow DOM, HTML Templates)はブラウザ標準でコンポーネントを実現する仕様として期待された。「ブラウザに組み込まれた公式のコンポーネント機能」と聞けば、それが最善の選択に思える。しかし現実には、いくつもの問題を抱えていた。
- リアクティビティの欠如: リアクティビティ(reactivity)とは「データが変わったら、そのデータに依存しているUIが自動的に更新される」性質
UI = f(state)のことだ。ReactのuseStateで値を更新すると画面が自動で変わるのは、Reactにリアクティビティの仕組みがあるからだ。Web Componentsにはこの仕組みがない。データの変更を検知してUIを更新するロジックを自前で実装する必要がある。つまり、コンポーネントの「箱」は提供されるが、中身の動き方は自分で全部作らなければならない - 構成性の限界: Shadow DOM(コンポーネントのスタイルが外に漏れないようにする仕組み)はあるが、コンポーネント間のデータの受け渡し(Reactのpropsに相当する機能)が貧弱
- エコシステムの分裂: 複数のライブラリ(Polymer, Lit, Stencil等)がそれぞれ異なるアプローチを取り、統一されたコミュニティが形成されなかった
- 標準化の遅延: W3C(Web標準の策定団体)での標準化プロセスに時間がかかる間にReact/Vue/Angularのエコシステムが成熟してしまった
W3CやブラウザベンダーがWeb Componentsの標準化に多大な労力を注ぎ込んだことで、開発者が本当に求めていた機能——リアクティビティシステムや宣言的なレンダリングAPI——の標準化にリソースが回らなかったという説もある。
6. フロントエンド/バックエンド分離の功罪
API + SPA分離はなぜ起きたか
Reactの普及に伴い、フロントエンド開発のアーキテクチャ(設計の構造)は大きく変わった。
従来のアーキテクチャ(MPA — Multi Page Application):
第4章で見たサーバーサイドMVCの構図がそのままMPA(Multi Page Application)だ。フロントエンドとバックエンドは同じアプリケーション内にあり、ユーザーがリンクをクリックするたびにサーバーが完成したHTMLを返し、ブラウザがページ全体を丸ごと表示し直す。「複数のページ間を遷移する」からMulti Page Applicationと呼ぶ。
SPA時代のアーキテクチャ(分離):
これに対して登場したのがSPA(Single Page Application)だ。SPAではページ遷移を行わず、最初に読み込んだJavaScriptがブラウザ上でUIを丸ごと構築・更新する。サーバーからはデータ(JSON)だけを受け取り、画面の書き換えはすべてクライアント側のJavaScriptが担う。この方式はCSR(Client-Side Rendering — クライアントサイドレンダリング)とも呼ばれる。
結果として、フロントエンド(React)とバックエンド(API)は別のアプリケーションに分離する。
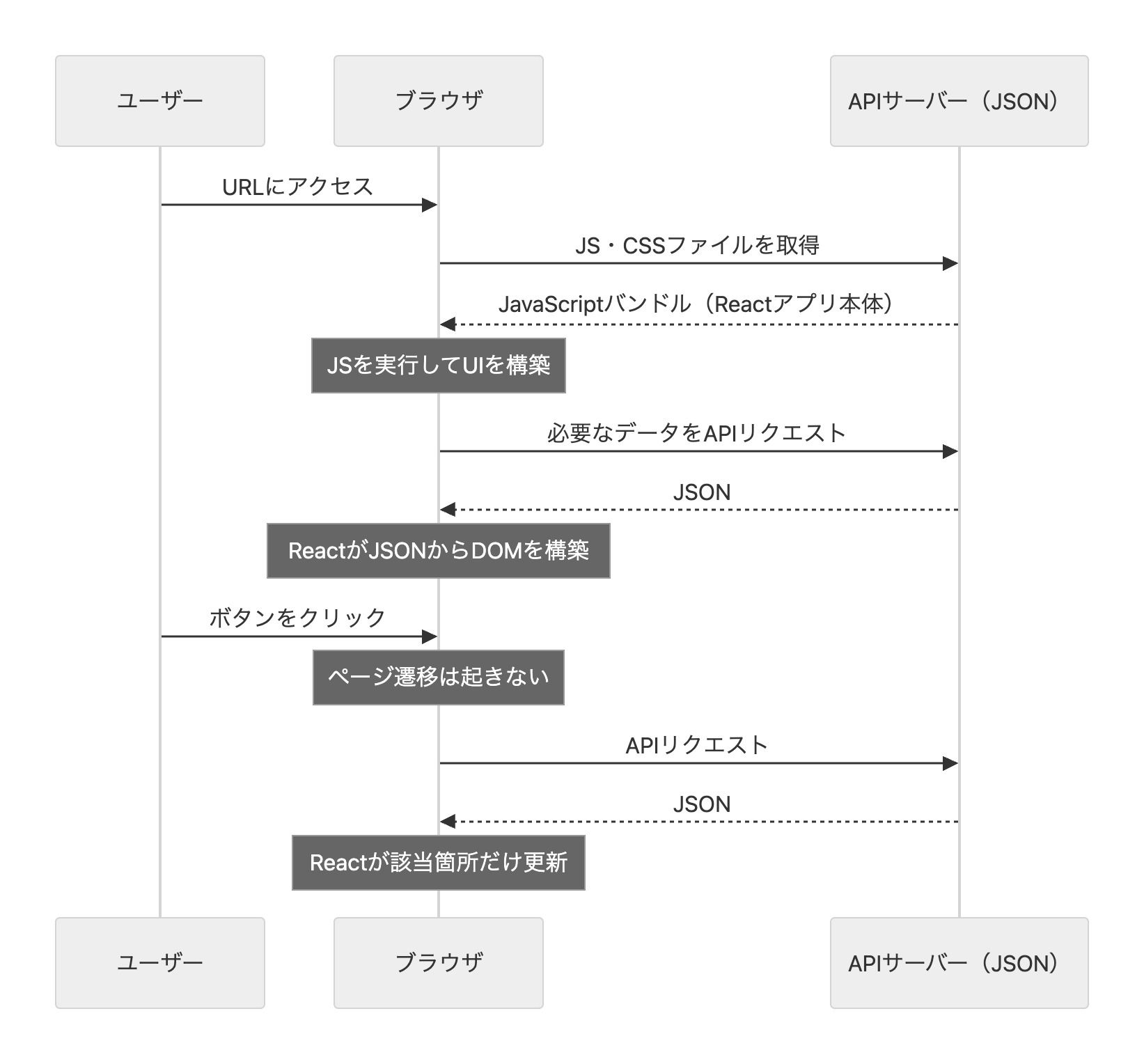
SPAでは初回アクセス時にJavaScriptのバンドル(アプリケーションのコード一式)をまとめて読み込む。そのため初回表示が遅くなりやすい。一方で、その後の操作ではページ全体の再読み込みが不要になるため、ネイティブアプリのような滑らかな操作感が得られる。
この分離には合理的な理由があった。
- UIの複雑さへの対応: クライアント側で豊かなインタラクションを実現するためにはフロントエンド専用のフレームワークが必要だった
- 分業の効率化: フロントエンドエンジニアとバックエンドエンジニアが独立して開発できる
- APIの再利用: 同じAPIをWeb、モバイルアプリ、外部サービスが共有できる
すべての操作でサーバーを経由するのは、レイテンシー(通信の遅延)的にも状態保持的にも無理があった。API + SPAという落とし所は、当時としてはバランスが取れた均衡点だったと言える。
分離がもたらした新たな問題
しかしこの分離はそれ自体が新たな複雑さを生んだ。
データのフェッチと同期の複雑さ:
SPAでデータを扱う際の典型的な処理フロー:
1. サーバーにAPIリクエストを送る
2. レスポンスが返ってくるまでローディング表示を出す
3. データが返ってきたらキャッシュに保存してUIに反映する
4. ユーザーが編集したら「楽観的更新」する
(サーバーの応答を待たずにUIを先に更新し、失敗したら巻き戻す)
5. 一定時間後にキャッシュが古くなったら再取得する
6. 別の画面で同じデータを使っていたら、そちらも更新する
→ この処理を全APIエンドポイントに対して書く必要がある
TanStack QueryやSWRのようなライブラリは、まさにこの「APIデータの取得・キャッシュ・再検証」を自動化するために生まれた。裏を返せば、それだけ複雑な処理が必要になっているということだ。
「型の二重管理」: APIのリクエスト/レスポンスの型(データの形)をフロントエンドとバックエンドの両方で定義・維持する必要がある。たとえばユーザー情報のAPIで email フィールドを追加したら、バックエンドのレスポンス型も、フロントエンドの受け取り型も、両方修正しなければならない。tRPCやGraphQLはこの問題への対処だ。
「フロントの地獄」: フロントエンドとバックエンドが分業してしまうことで溝が深まり、フロントエンド側に複雑さが集中するという構造的な問題がある。APIの設計、状態の同期、エラーハンドリング、ローディング状態の管理——これらは全て「フロントとバックが別アプリである」ことから生まれる問題だ。
現場のReactコードが複雑化する原因は、React自体の問題というよりも、JSON APIおよびフロントエンド/バックエンドを分離させて別アプリにしていることに起因しているという見方がある。この指摘は、HotwireやRSC(React Server Components)が登場した文脈を理解する上で極めて重要だ。これらの技術は、一度分離されたフロントエンドとバックエンドを再び接近させようとする試みである。
もっとフロントエンドエンジニアがサーバーを触り、バックエンドエンジニアがクライアントを触れば状況は良くなる。HotwireにしろRSCにしろ、そういう前提のもとに設計されている。
第3部: Reactへの批判とその検証
7. 「Reactは時代遅れ」論の検証
Signalsとは何か — Reactへの技術的対案
「Reactはもう時代遅れだ」という主張がある。例えば、Reactではネストしたオブジェクトの一部を更新するだけでも、スプレッド演算子(... を使ってオブジェクトを展開する構文)を多用しなければならない。
// Reactでネストした状態を更新する例
// user.address.city だけを変えたいのに、各階層を展開する必要がある
setUser({
...user,
address: {
...user.address,
city: "Tokyo"
}
});
階層が深くなるほどこの記述は煩雑になる。今の時代、JavaScriptのオブジェクト自体にリアクティビティ(第5章参照)を授けるアプローチがあり、面倒な作法はもはや不要だという見方もある。
この文脈で登場するのが「Signals」という概念だ。ReactとSignalsの違いを理解するには、「UIの更新範囲」に注目するとわかりやすい。
Reactの更新モデル(粗粒度リアクティビティ):
function Counter() {
const [count, setCount] = useState(0);
const [name, setName] = useState("");
// ボタンを押して count を 0→1 に変えると...
// Reactは「Counterコンポーネント全体」を再実行する。
// つまり、この関数がまるごともう一度呼ばれる。
// nameは変わっていないのに、nameを表示する部分も再評価される。
// その後、仮想DOMの差分で「実際にDOMを変える必要があるのはcountの部分だけ」と判定する。
return (
<div>
<p>{name}</p> {/* nameは変わっていないが、再評価はされる */}
<p>{count}</p> {/* ここだけ実際に変わる */}
<button onClick={() => setCount((c) => c + 1)}>+</button>
</div>
);
}
Reactでは、ある状態が変わるとコンポーネント関数全体が再実行される。その後、仮想DOMの差分比較で「実際にDOMを変える必要があるのはここだけ」と判定し、最小限のDOM更新を行う。関数の再実行自体は速いが、コンポーネントが巨大になると無駄も大きくなる。
Signalsの更新モデル(細粒度リアクティビティ):
// SolidJS(Signals系フレームワークの一つ)の例
function Counter() {
const [count, setCount] = createSignal(0);
const [name, setName] = createSignal("");
// countを0→1に変えると...
// SolidJSは「countを使っているDOM箇所だけ」をピンポイントで更新する。
// 関数全体の再実行は起きない。仮想DOMの差分比較も不要。
// nameの部分は一切触られない。
return (
<div>
<p>{name()}</p> {/* countが変わってもここは何もしない */}
<p>{count()}</p> {/* ここだけ直接DOM更新 */}
<button onClick={() => setCount((c) => c + 1)}>+</button>
</div>
);
}
イメージとしては、Reactは「状態が変わったらページ全体の写真を2枚撮って見比べる」方式。Signalsは「状態と表示が糸で直接つながっていて、値が変わると糸を伝って表示だけが変わる」方式だ。
Signals(SolidJS, Vue, Svelte 5 Runes, Angular Signals, Preact Signals)は、どの値がどのUI要素に依存しているかを追跡し、値が変わった時にその値を使っている箇所だけをピンポイントで更新する。この動きは業界全体のトレンドで、2024年にはTC39(JavaScript標準化委員会)でSignalsをJavaScript言語標準にする提案がStage 1に到達した。
批判の妥当性と限界
「スプレッド演算子の多用」「ネストの深さ」という批判は、ReactのImmutability(不変性)の原則に起因する。
Immutabilityとは「データを直接書き換えず、常に新しいコピーを作って置き換える」という原則だ。なぜReactがこの原則を採用しているかというと、「前回のデータ」と「今回のデータ」を比較して差分を検出するために、前回のデータがそのまま残っている必要があるからだ。
// Reactでのネストしたオブジェクトの更新(確かに面倒)
// 「ユーザーの住所の都市名だけ変えたい」場合:
setUser((prev) => ({
...prev, // ユーザー全体をコピーして
address: {
...prev.address, // 住所もコピーして
city: "Tokyo", // 都市名だけ変える
},
}));
// → cityだけ変えたいのに、3段階のコピーが必要
これは確かに冗長だ。しかし実務では、いくつかの方法で対処できる。
- Immerのようなライブラリを使えば
produce(user, draft => { draft.address.city = 'Tokyo' })と書ける(見た目上は直接書き換えているように書けるが、内部では新しいコピーが作られる) - そもそも設計が良ければ深いネストは避けられる。たとえば
user.address.cityのように深くネストした一つのオブジェクトではなく、userとaddressを別々のstateとして管理すれば、setAddress({ ...address, city: 'Tokyo' })の1段で済む - グローバル状態はZustandやJotai等の軽量ライブラリが解決する
Signalsは確かにReactの特定の課題(更新粒度の粗さ、Immutabilityの冗長さ)に対するエレガントな解だ。しかしReactからSignals系フレームワークへの移行は「Reactの問題を解決する」というよりも「異なるトレードオフを選ぶ」ことに近い。ReactのImmutabilityには「どの時点のデータでも保持されているので、タイムトラベルデバッグ(過去の状態に戻って確認する)がしやすい」「データの変更が明示的なので、予測しやすい」というメリットがある。Signals系が「Reactがダメだから」生まれたのではなく、「更新粒度を細かくしたい」という別のアプローチとして存在しているのだ。
「忘れられる歴史」
宣言的UIフレームワークが近年解決しようとしてきた数多の課題は、驚くほど簡単に忘れられる。Reactの複雑さに不満を持つ人は多いが、その複雑さが何を解決するために存在しているかを理解せずに「不要」と断じる議論が繰り返される。宣言的UIという発明があったということ——少なくともそれだけは事実である。
8. 「ReactはPolyfillだった」論の検証
Polyfill論の主張
「ReactはPolyfill(ポリフィル)に過ぎなかった」という主張がある。ポリフィルとは、ブラウザが対応していない機能を、JavaScriptのコードで補う互換ライブラリのことだ。たとえば、古いブラウザで Array.prototype.includes が使えない場合に、同じ機能を提供するコードがポリフィルだ。
この論の主張はこうだ。
- 2013年当時、ブラウザのAPIが未熟だったからReactが必要だった
- 現在はブラウザの標準機能が進化した(
<dialog>,<template>, CSS animations, View Transitions API等) - よって、Reactが担っていた役割の多くはもう標準機能でカバーできる
- 結論: ReactよりもWeb標準 + 軽量なツール(htmx/Hotwire + Tailwind)が最適解
進化したブラウザAPI — 実際に何がカバーできるようになったか
確かにブラウザは大きく進化した。
| かつてJSが必要だった機能 | 現在の標準対応 |
|---|---|
| モーダルダイアログ | <dialog> 要素(フォーカストラップやEscキーの閉じ処理を自動で行う) |
| アコーディオン | <details> / <summary> 要素(クリックで開閉する折りたたみUI) |
| フォームバリデーション | HTML5 Constraint Validation API |
| アニメーション | CSS Transitions / Animations / Web Animations API |
| スクロール制御 | scroll-behavior: smooth, scroll-snap |
| レスポンシブデザイン | Container Queries, :has() セレクタ |
| ページ遷移 | View Transitions API(ページ間の滑らかな遷移アニメーション) |
これらはReactなしで実現できるようになった。単純なWebサイトであれば、確かにReactは不要だ。
Polyfill論の根本的な誤り
しかし、Polyfill論には根本的な見落としがある。Reactの主要な意義は、DOMのAPIを便利にすることではない。
ブラウザが追いついた領域(UIの「見た目」の問題):
・モーダルの表示 → <dialog>
・アニメーション → CSS
・フォームバリデーション → HTML5
Reactの本質的な領域(UIの「構造」の問題):
・状態と外観の分離(UI = f(state))
・コンポーネント化と再利用
・再描画最適化(差分更新)
<dialog> タグでモーダルを表示できるようになっても、「データが変わったらUIを自動更新する」「UIを再利用可能なコンポーネントに分割する」という問題は解決されない。これらはブラウザの個別APIの問題ではなく、UIをどう構造化するかというアーキテクチャの問題だ。
ブラウザ互換性の穴埋めはjQueryの役割であって、Reactの役割ではなかった。Reactの本質をAPIの穴埋めと捉えること自体が、宣言的UIの意義を十分に理解していないことの表れだとも言える。
ただし正当な部分もある。全てのWebサイトにReactが必要なわけではない。静的なコンテンツサイトや、インタラクションが限定的なサイトでは、HTML + CSS + 少しのJSで十分だ。問題は「Reactが不要なケースがある」ことと「Reactの意義がPolyfillに過ぎない」ことは別の主張だという点だ。
9. セマンティックWeb・アクセシビリティの破壊という批判
ReactはセマンティックHTMLを破壊したのか
「ReactはセマンティックWeb(HTMLの各要素にふさわしい意味的役割を持たせる考え方)を破壊した」という批判がある。
セマンティックHTMLとは何か。HTMLの各要素には本来、意味がある。<nav> は「ナビゲーション」、<button> は「ボタン」、<a> は「リンク」。ブラウザはこの意味を理解して、<button> ならキーボードのEnterで押せるようにし、<a> ならリンク先を表示する、といった処理を自動で行ってくれる。スクリーンリーダー(視覚障害のあるユーザーが使う読み上げソフト)も、「ここはナビゲーション、ここにリンクが3つ」と読み上げられる。
<!-- セマンティックなHTML — 要素に意味がある -->
<nav>
<!-- 「ここはナビゲーション」 -->
<ul>
<li><a href="/home">Home</a></li>
<!-- 「ここはリンク」 -->
<li><a href="/about">About</a></li>
</ul>
</nav>
<!-- Reactで見られがちな非セマンティックなHTML — 全部 <div> -->
<div class="nav">
<!-- divには意味がない -->
<div class="nav-item" onClick="{goHome}">Home</div>
<!-- これがリンクかボタンか不明 -->
<div class="nav-item" onClick="{goAbout}">About</div>
</div>
<!-- → スクリーンリーダーは「ここにテキストが2つある」としか分からない -->
<!-- → キーボードだけでは操作できない(divはTabキーでフォーカスできない) -->
React製のWebサイトには <div> と <span> で全てを構成し、セマンティックな要素を使わないものが多い。さらに、来たるAIエージェントが支援するブラウザの時代には、HTML要素の意味を無視した設計のWebサイトほど操作しにくくなり、ユーザーが離れるだろうという予測もある。
「HTMLサイト」と「JSアプリ」は別物
この批判に対する反論も存在する。JSが無効でも使える「HTMLサイト(第6章で見たMPA)」と、JS前提で設計する「JSアプリ(SPA)」は思想が全く異なるという考え方だ。
年表で触れたように、Webは本来ドキュメントのプラットフォームだった。<article>, <nav>, <header> といった要素は、文書の構造を表現するためのものだ。GoogleマップやFigma、Notionのような複雑なアプリケーションを「ドキュメント」のセマンティクスで表現すること自体に無理がある。
SPAがWebの上で動いているのは、Webが最も普及したプラットフォームだからであって、HTMLの設計意図に沿っているからではない。
「理想的なSPAは、MPAの上で動くべきだ」という主張もある。一見矛盾して聞こえるが、これは「基本はMPA(サーバーがHTMLを返す通常のWebサイト)として正しく構造化しておき、リッチなインタラクションが必要な部分だけJavaScriptで拡張する」という考え方だ。全てをJavaScriptで構築するのではなく、まず土台としてのHTMLドキュメントがあり、その上にSPA的な体験を載せる。こうすれば、JavaScriptが無効でも最低限のコンテンツは読めるし、セマンティクスも維持できる。Next.jsのようなフレームワークがSSR(サーバーサイドレンダリング。サーバー側でHTMLを生成する方式で、第12章で詳述する)を重視するのも、この方向性の一つと言える。
第4部: ポストReact — 現代の選択肢
10. Hypermedia駆動の復権 — htmxとHotwire
「復古運動」としてのHypermedia
ReactをはじめとするSPAフレームワークは、ブラウザを「アプリケーションの実行環境」として扱う。HTMLは単なるコンテナで、実質的なUIはJavaScriptが構築する。
一方htmxやHotwireは、ブラウザを本来の「HTMLを解釈するプラットフォーム」として扱い、サーバーがHTMLを返すというWebの基本的な動作を拡張する。
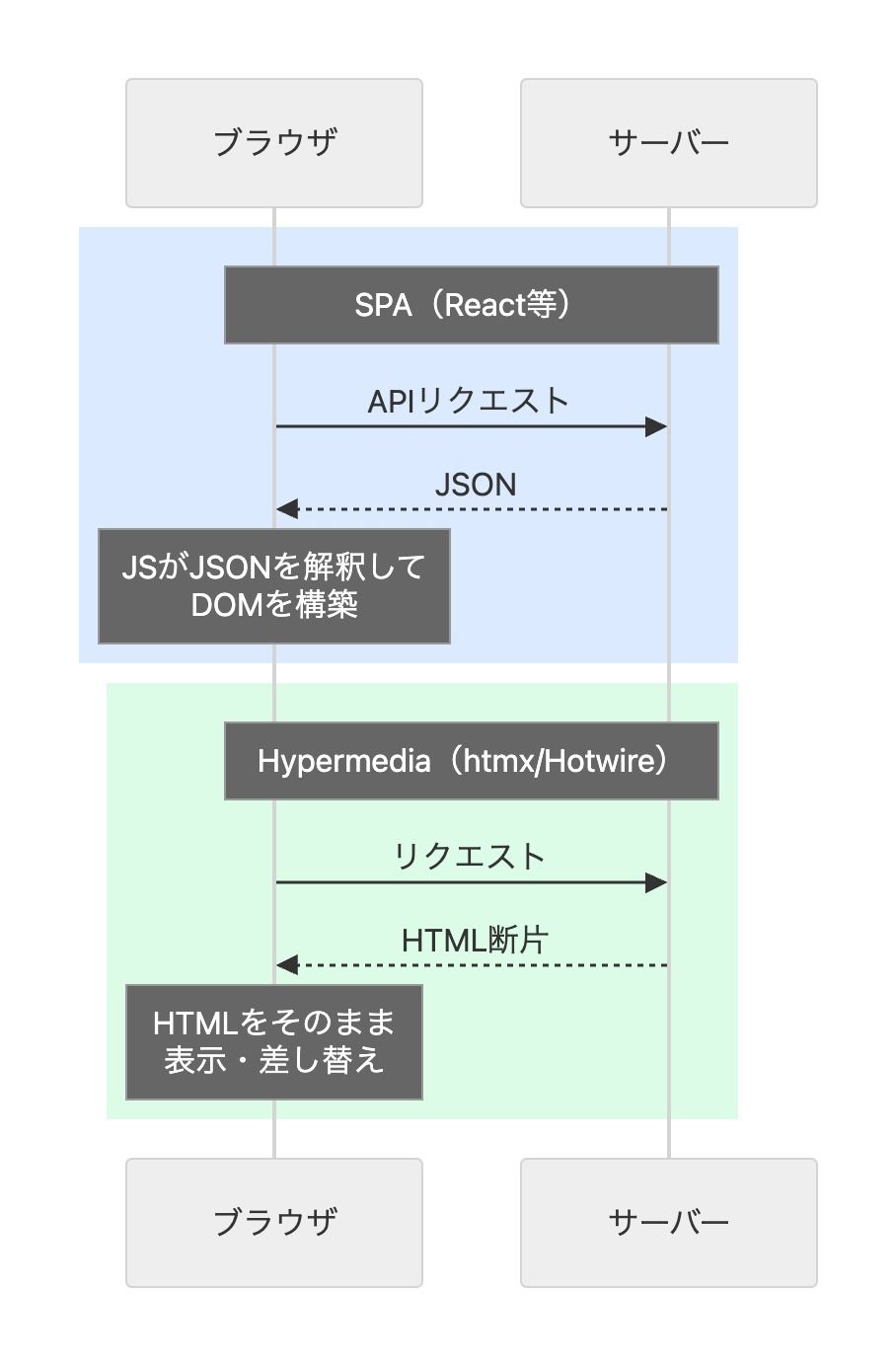
これはWebの本来の姿を取り戻す復古運動だという見方がある。Webブラウザは仮想マシンの中の「アプリ」の器ではなく、ハイパーメディア(テキスト・画像・リンクなどを統合した情報表現)を解釈する分散ドキュメントプラットフォームだという立場だ。
実際、Reactが解こうとしている問題——複雑な状態管理を伴うリッチなインタラクション——を必要とするWebサイトは、Web全体のほんの一部だ。企業のコーポレートサイト、ブログ、ECサイトの商品一覧、ニュースサイト......世の中のWebサイトの大半は小規模かつ単純で、サーバーがHTMLを返すだけで十分に機能する。こうしたサイトには、htmxやPHP、Hotwire/Stimulusといった技術の方が適している可能性が高い。
出自の違いが設計に及ぼした影響
技術の出自がその設計思想に大きく影響するという観点は重要だ。
Hotwire(37signals / Basecamp / HEY):
- 実際の商用SaaS製品(Basecamp, HEY)の開発から生まれた
- UIに対する現実的な要求に応えることが最初から求められていた
- 37signals CEOのJason Friedはデザイナー出身であり、UI/UXの妥協は許されなかった
- 結果: カスタムJSが必要な場面に対応するStimulus、リアルタイム更新のTurbo Streamsなど、現実の要求に応える構造が最初から設計に含まれている
htmx(Carson Gross / モンタナ州立大学):
- アカデミックな文脈から生まれた
- Hypermedia(ハイパーメディア)の理論的純粋さを重視する傾向がある
- 商用製品への直接的な責任がない分、理論に寄った設計になりやすい
- 結果: HTMLに密着したプリミティブな操作を提供する。理論の純粋さが設計に色濃く反映されている
フロントエンドは人間とのインタフェースであるため、論理的でない要件が複雑化しやすい。「この画面ではアニメーション付きでモーダルを出したい」「このフォームだけ特殊なバリデーションが必要」といった例外ケースが必ず出てくる。Hotwireの場合はそうした例外に対応する仕組み(Stimulus)が最初から設計に含まれていた。こうした出自の違いが設計にどう影響するかは、第11章・第13章でさらに掘り下げる。
この構造はフレームワーク全般に当てはまる。Angular/ReactがGoogle/Facebookという巨大企業から生まれたのは偶然ではなく、大規模で複雑なアプリケーションの課題が設計に反映されている。一方、Rails, Hotwire, htmxが小さいチームから生まれたことは、シンプルさの重視として設計に表れている。
選択肢の多様性
新しく業界に入ってくる若手に提示される選択肢が実質Reactしか無くなっていることへの懸念もある。現実に、React以外の技術がマッチする現場も数多くある。React一強の状況は業界にとって健全ではなく、htmxやHotwireといった別の選択肢を知っておくことには価値がある。
11. htmx批判の2つの論点
批判の構造
htmxに対する批判は、大きく2つの論点に分けられる。
論点1: HTML on the Wire自体への批判
「サーバーがHTMLを返して状態を表現する」というアプローチそのものへの批判だ。「JSONを返してクライアントで描画する方が柔軟だ」という立場から出てくる。しかしこのアプローチ自体には有効活用の可能性があるという見方が多い。実際、RSCも本質的にはサーバーでUIを構築してクライアントに送るアプローチであり、HTML on the Wireの思想と近い。
論点2: htmxの手続き的な記述への批判
こちらがより深刻な批判だ。HTML on the Wire(サーバーがHTMLを返す方式)は、本来は宣言性を高めるはずの方向性だ。なぜなら、サーバーが「UIのあるべき姿」を完成されたHTMLとして返してくれるので、クライアント側で「データを受け取って、DOMを組み立てて、状態を管理して...」という手続きが不要になるからだ。しかしhtmxでは、その返ってきたHTMLを「どこに」「どうやって」差し込むかという指示をHTML属性として各要素にバラバラに記述する必要がある。せっかく宣言性を上げる方向に進んだのに、部分更新の記述がまた手続き的になってしまうというジレンマ。
<!-- htmx: 何をトリガーに何をどこに差し込むかがHTML中に散在する -->
<button hx-get="/items" <!-- クリックで /items にGETリクエスト -->
hx-target="#list" <!-- レスポンスを #list に差し込む -->
hx-swap="innerHTML" <!-- 差し込み方法: 中身を丸ごと置換 -->
hx-trigger="click" <!-- トリガー: クリック -->
hx-indicator="#spinner"> <!-- 通信中に #spinner を表示 -->
Load Items
</button>
<div id="list"></div>
<div id="spinner" class="htmx-indicator">Loading...</div>
<!-- 別の場所にまた別のhtmx属性 — どちらが先に実行されるかは操作順次第 -->
<input hx-get="/search" <!-- キー入力で /search にGETリクエスト -->
hx-target="#results" <!-- レスポンスを #results に差し込む -->
hx-trigger="keyup changed delay:300ms"> <!-- 300ms入力が止まったら発火 -->
<div id="results"></div>
各要素にhtmx属性が散在し、「何がどう連携しているか」の全体像を把握するには、HTML全体をスキャンしなければならない。この散在性はjQuery時代の「どこで何を操作しているか追跡できない」問題と構造的に同じだ。
Hotwireの対照的なアプローチ
対照的なのがHotwire/Turboの設計だ。
<!-- Hotwire/Turbo: フレームという明示的な境界 -->
<turbo-frame id="notifications">
<!-- この枠の中のリンクやフォームは、この枠の中だけを更新する -->
<!-- 枠の外には影響しない — 境界が構造として明示されている -->
<a href="/notifications">通知一覧を読み込む</a>
<!-- ↑ このリンクをクリックすると、サーバーからHTMLが返ってきて、
turbo-frame id="notifications" の中身だけが置き換わる -->
</turbo-frame>
Turbo Framesは「この枠の中だけが更新対象」という境界をHTMLの構造として明示する。これは<iframe>(別のページを埋め込む要素)の概念をモダンに再解釈したもので、開発者が「どこが更新されるか」を構造的に把握できる。
htmxにはTurboに見られるようなフレーム概念がなく、従うべきレール(指針)が示されない。思想が伝わらないと容易くはみ出てしまう結果になる。Turbo Framesのフレーム概念は、iframeからの着想による「概念的距離の圧縮」——つまり馴染みのある概念を使って新しい抽象を作る——と言える見事な設計だ。
12. React Server Components — フロントエンドの再統合
RSCが示す方向性
SSR — CSR SPAの課題を補う試み
第6章で見たように、CSR(クライアントサイドレンダリング)のSPAではブラウザがまず空のHTMLとJSバンドルを受け取り、JavaScriptがゼロからUIを構築する。この方式には根本的な課題があった。
- 初回表示が遅い: 大量のJSをダウンロード・実行し終えるまで画面に何も表示されない
- SEOに不利: 検索エンジンのクローラーが取得するHTMLが空(
<div id="root"></div>だけ) - 低スペック端末に厳しい: UIの構築をすべてクライアント側のJSに依存する
SSR(Server-Side Rendering)は、この課題に対する直接的な解決策だ。サーバー上でReactを実行し、コンポーネントツリーをHTMLに変換してからクライアントに返す。ブラウザはまずそのHTMLを表示するので、ユーザーはJSの実行を待たずにコンテンツを目にすることができる。
しかし、サーバーが返したHTMLは最初の時点ではただの静的なHTML——つまりボタンを押しても何も起きない、ただ表示されているだけの状態だ。ここで必要になるのがハイドレーションという処理だ。ハイドレーションとは、この静的なHTMLにクライアント側のJavaScriptを「水を注ぐように」結びつけて、ボタンのクリックなどのインタラクションが効くようにする処理のことだ。
SSRの限界は、このハイドレーションにある。SSRではページ全体のコンポーネントに対応するJavaScriptをクライアントに送り、ページ全体をハイドレーションする必要がある。つまり、表示は速くなったが、インタラクティブになるまでの待ち時間とJSバンドルの大きさはCSR SPAと変わらない。Next.js Pages Router(2016年〜)がこのSSRの代表的な実装だ。
React Server Components(RSC)は、SSRをさらに進化させたアプローチであり、React自身による「フロントエンド/バックエンド分離の弊害への回答」でもある。RSCの核心は、コンポーネントをServer ComponentとClient Componentに分けることだ。Server Componentはサーバー上でのみ実行され、クライアントにJavaScriptを一切送らない。Client Componentだけがハイドレーションの対象になる——つまり、静的な部分のJSは不要になり、クライアントに送るJSの量が大幅に減る。
以下の図で、CSR SPA・SSR・RSCの3つのアプローチを比較する。
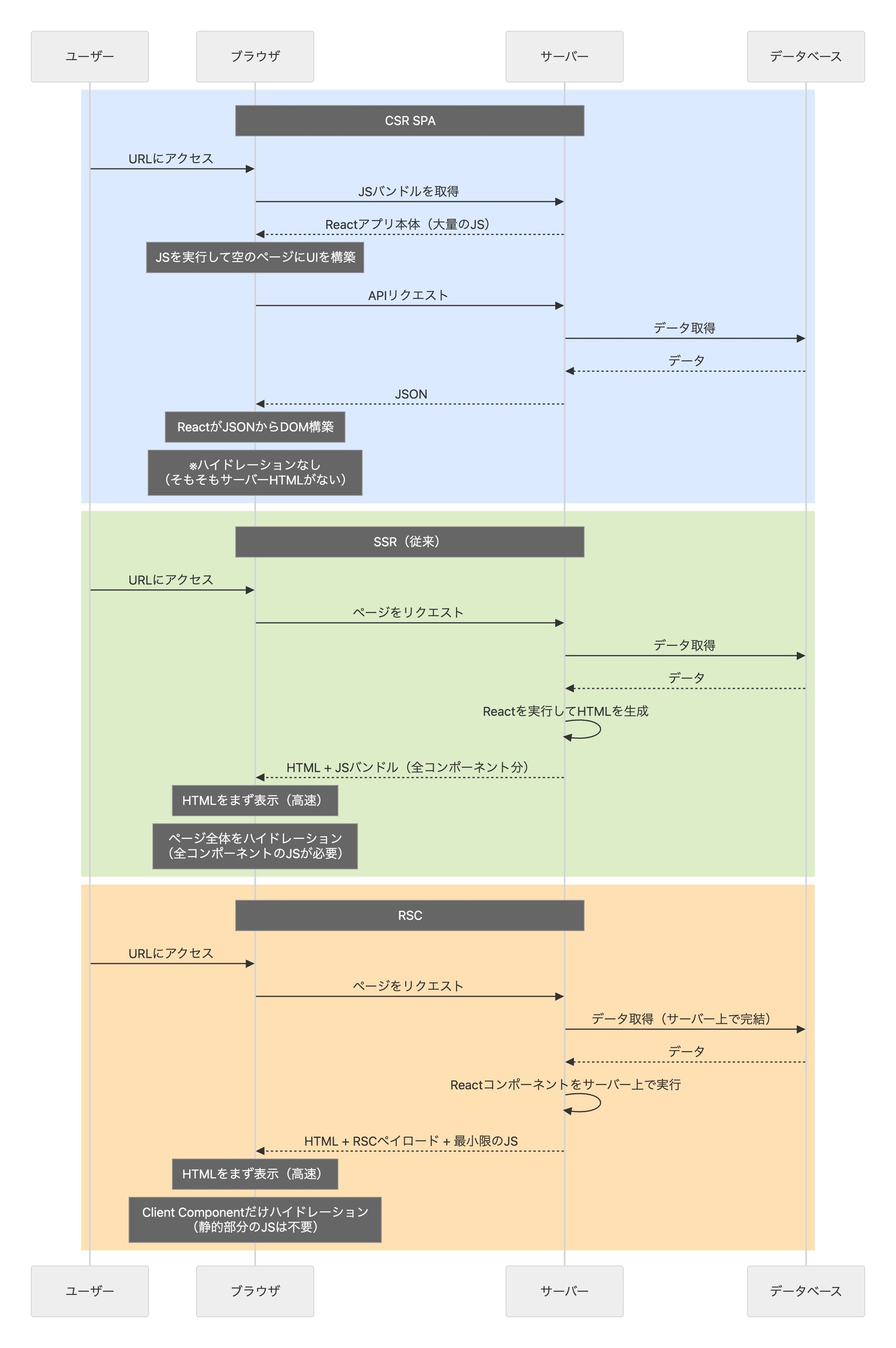
RSCではサーバー上でReactコンポーネントが実行され、その結果(RSCペイロードと呼ばれる独自フォーマット)がクライアントに送られる。
RSCにより以下が実現される。
- データベースクエリをコンポーネント内で直接書ける(API層が不要になる)
- クライアントに送るJSバンドルが大幅に削減される
- サーバー状態のクライアント側キャッシュ管理(TanStack Query等)が不要になる
注目すべきは、HTML on the WireとRSCペイロードの世界観がかなり近接していることだ。
htmx/Hotwire: サーバー → HTML断片 → クライアントがDOM差し替え
RSC: サーバー → RSCペイロード → Reactがコンポーネントツリー更新
形式は違うが、「サーバーでUIを構築してクライアントに送る」という方向性は同じ
フロントエンド/バックエンド分離の時代を経て、フロントエンドは再びサーバーサイドとの統合に向かっている。気づいたら数年後は、形は違えどみんなHypermediaの世界に近づいているかもしれない。
RSC(ないしはNext.js)の課題
RSCは現時点ではNext.jsが最も先行した実装を持っている。しかし、Next.jsによるフルスタック開発には課題も見えてきている。Reactと密結合しすぎていること、Server ComponentとClient Componentの境界が曖昧でどこまでがサーバーの責務なのか分かりにくいこと、そしてRailsやLaravelなどの成熟したバックエンドフレームワークが標準で持つ機能群——認証、認可、ORM(データベース操作の抽象化層)、バックグラウンドジョブ、メール送信、ファイルストレージ操作——といったエコシステムがNext.jsには欠けている。フロントエンドフレームワークがバックエンドの領域に踏み込むことで、かえって中途半端な状態が生まれるリスクがあるのだ。
第5部: フレームワークの哲学と設計思想
13. 哲学は実装を正当化するが、実装を制約しない
本章と次章で紹介する「降下深度」「構造的盲点」という考え方は、@yuta0801_氏のX(Twitter)上での記事1および記事2で展開されていたものだ。非常に示唆に富む内容だったので、勝手に紹介させていただく。
「降下深度」の概念
技術的な思想やデザイン哲学には、どのレイヤーまで降りてくるかという「深度」がある。これを「降下深度」と呼ぶ考え方がある。
具体例で見てみよう。Web開発者にも馴染みのある例から始める。
降下深度のスペクトラム(深い方が思想の実効性が高い)
[最も深い] 言語レベル
TypeScriptの型チェック → 型が合わないとコンパイルエラー。
例: 数値を期待する関数に文字列を渡すと、コードを実行する前にエラーになる。
思想を無視するとプログラム自体が動かない。
Rustのownership → メモリ安全でないコードはコンパイルエラー。回避不能。
哲学を守らない選択肢が物理的に存在しない。
[深い] フレームワーク構造レベル
ReactのuseState → 詳細は次章で解説する。
Turbo Frames → HTMLの構造として更新境界を明示。
フレームの外を更新しようとしても、フレームワークが許さない。
[中間] 規約レベル
Rails CoC(Convention over Configuration)→ ディレクトリ構造の規約。
「コントローラはapp/controllers/に置く」という規約。逸脱は可能だが、摩擦が生じる。
[浅い] ドキュメントレベル
htmxのRESTful思想 → READMEや書籍に書いてある。
コードは何も制約しない。読まなければ伝わらない。
[最も浅い] スローガンレベル
「シンプルにしよう」→ 何も制約しない。誰でも賛成するが、何も変わらない。
この深度の概念を同じHypermedia駆動のhtmxとHotwireに適用すると、決定的な違いが明確になる。Hotwireは思想を構造(Turbo Frames)に降ろしている。htmxは思想をドキュメント(Hypermedia Systems書籍)に留めている。
「免罪符としての哲学」
この深度の概念を理解すると、ある危険性が見えてくる。哲学が美しいほど、それと乖離した実装との距離が目立たなくなるのだ。
第11章で見たhtmxとHotwireの対比がここでも当てはまる。htmxのRESTful思想やHypermedia哲学はREADMEや書籍には美しく書かれているが、降下深度としてはドキュメントレベルに留まる。hx-on属性でインラインJavaScriptを書いても、Alpine.jsを混在させて複雑な状態管理を持ち込んでも、フレームワークは何も制約しない。
「htmxを使っている」→「Web本来のアーキテクチャに従っている」(思想的正当性の錯覚)
「Agile開発をやっている」→「正しいプロセスで開発している」(思想的正当性の錯覚)
「マイクロサービスにした」→「疎結合な設計になっている」(思想的正当性の錯覚)
いずれも、思想を採用したことと、思想に沿った実装をしていることは別の問題だ。
14. 構造的盲点 — 構造は思想を伝えるが、届かぬ領域に盲点を生む
構造が「教える」こと
フレームワークの構造は、開発者にその思想を自然と体得させる力を持っている。ReactのuseStateはその好例だ。
// やってみよう: 普通の変数でカウンターを作る
let count = 0;
function Counter() {
return <button onClick={() => count++}>{count}</button>;
// ボタンを押すとcountは増える...が、画面は「0」のまま変わらない!
// → 「普通の変数を変えてもReactは気づかない」と学ぶ
}
// 正解: useStateを使う
function Counter() {
const [count, setCount] = useState(0);
return <button onClick={() => setCount((c) => c + 1)}>{count}</button>;
// setCountを呼ぶと、Reactが「状態が変わった」と認識し、画面を更新してくれる
}
「UIは状態の関数である」という思想は、ドキュメントを読まなくても、正しく動くコードを書く過程で体得される。stateを直接書き換えても画面は更新されない。setStateを呼ぶことで再レンダーが走る。この「動く/動かない」の摩擦と応答の繰り返しが、宣言的UIという思想を開発者に刻み込む。
構造が「教えない」こと — useEffectの悲劇
一方、useEffect は構造が思想を伝えることに失敗した代表例だ。
useEffect はReactの中で「副作用(UIの描画以外の処理)」を扱うための仕組みだ。本来は「外部システムとの同期」——たとえばWebSocketの接続やタイマーの設定——に使うものだった。
// ✅ useEffectの「正しい」使い方(外部システムとの同期)
// 「urlが変わったら、WebSocket接続を張り直す」
useEffect(() => {
const ws = new WebSocket(url); // 接続を開く
ws.onmessage = handler;
return () => ws.close(); // コンポーネントが消える時に接続を閉じる
}, [url]); // urlが変わった時だけ実行
// ❌ useEffectの「誤用」その1(派生状態の計算)
// 「firstNameかlastNameが変わったら、fullNameを更新する」
useEffect(() => {
setFullName(firstName + " " + lastName);
}, [firstName, lastName]);
// → これはuseEffectを使わなくても、単にconst fullName = firstName + ' ' + lastName で済む
// → わざわざuseEffectで状態更新すると、不要な再レンダーが発生する
// ❌ useEffectの「誤用」その2(イベントハンドラの代替)
// 「submittedがtrueになったら、分析データを送る」
useEffect(() => {
if (submitted) {
sendAnalytics();
}
}, [submitted]);
// → これはフォーム送信のイベントハンドラの中で直接sendAnalytics()を呼べばいい
useEffectは「何でもできる汎用的なAPI」として設計されたが、どう使うべきかは構造からは伝わらなかった。useStateの場合は「使わないと画面が更新されない」という明確な摩擦があったが、useEffectは誤用しても「一応動く」のだ。ただし不要な再レンダーが発生したり、無限ループに陥ったりと、問題は後から忍び寄ってくる。
「これはエスケープハッチ(緊急脱出口)だ」「外部システムとの同期にだけ使え」という思想はReactチームの頭の中にはあったが、APIの設計としては表現されていなかった。React公式ドキュメントが「You Might Not Need an Effect(useEffectは不要かもしれない)」という記事を公開したのは、この問題が広く認識された後のことだった。
構造的盲点はどこにでもある
この問題はReactに限らない。構造が届いている領域の存在が、届いていない領域への注意を鈍らせる。Reactのコンポーネントモデルは見事に機能していたがゆえに、開発者は「Reactを理解して使っている」という感覚を持ち続けた。その感覚の中で、useEffectの誤用は静かに蓄積した。
同じ「構造的盲点」は他の技術にも現れる。
- TypeScript: 型チェックは通っているが、型設計がドメイン(業務領域)の実態を表現しているかは別問題。「型エラーが出ないから安全」とは限らない
- GraphQL: クライアントからクエリを自由に書ける柔軟性はあるが、「どのデータをどのコンポーネントが責任を持つか」は構造からは見えない
- マイクロサービス: サービスに分かれているが、分け方が正しいかは構造からは見えない。分かれていること自体が「疎結合にできている」という錯覚を生む
- テスト: テストが存在し、CIで緑色のチェックが付いているが、何を保証しているか(カバレッジの意味)は構造からは見えない
いずれも「構造がある」という事実が、「構造が届いていない領域」への注意を鈍らせている。
15. 技術選定で問うべきこと
問うべき3つの問い
ここまでの議論全体を通じて浮かび上がるのは、技術選定で問うべき3つの問いだ。
問い1: その哲学は、どのレイヤーで実装に降りているか
前章の「降下深度」の概念を適用する。思想がドキュメントやスローガンに留まっているなら、その思想を維持する責任はチームに降りかかる。構造的制約として実装に降りているなら、フレームワークが自然にガイドしてくれる。
フレームワークの哲学に共鳴したなら、次に問うべきは「その哲学は、私たちのコードにどうやって降りてくるのか」だ。答えが「自分たちで規律を持つ」であるなら、それは設計の問題として引き受ける必要がある。
問い2: その技術は何を解決するために存在しているか
第7章で触れた通り、技術が解決してきた課題は忘れられやすい。技術が生まれた歴史的文脈を理解することが重要だ。なぜjQueryではだめだったのか、なぜReactが生まれたのか、なぜhtmxが登場したのか——それぞれの技術が「何に対する解」なのかを理解しなければ、適切な選定はできない。
問い3: 開発者体験とユーザー体験の両方を長期的に向上させるか
3つの問いの中で最も本質的なものだ。哲学の美しさでも、技術的なエレガンスでもなく、実際にコードを書く開発者と、それを使うユーザーの体験を長期的に向上させるかどうか。ここには「十分な連続性」——つまり今日の学びが明日も活きるか、技術の成長とともに開発者も成長できるか——という時間軸の問いも含まれている。
まとめ
フロントエンド技術の歴史は、以下の必然性の連鎖として理解できる。
バニラJS: DOMを操作する手段がプリミティブすぎた
↓ DOM操作を便利にしたい
jQuery: DOM操作は便利になったが、状態管理の構造がなかった
↓ データとUIを自動で同期したい
React: 宣言的UI(UI=f(state))で状態とUIの同期を解決した
↓ UIのために専用のフロントエンドアプリが必要になった
SPA + API分離: UIの複雑さに対処できたが、FE/BE分離が新たな複雑さを生んだ
↓ 分離の弊害を解消したい
htmx/Hotwire: サーバーにUIの責任を戻す「復古運動」
RSC: React自身がFE/BE再統合に向かう
Signals: Reactとは異なるリアクティビティモデルの提案
各技術は前の時代の問題に対する解であり、同時に新たな問題を内包している。「最善の技術」は存在せず、問題の性質とトレードオフの組み合わせとして選定するしかない。その選定において、哲学の美しさに惑わされず、構造的制約の実効性と、歴史が教える教訓を踏まえることが重要だ。
新しく業界に入る人にとって、選択肢がReact一つしかないように見えるのは不幸なことだ。しかし同時に、Reactが解決してきた問題を理解せずに、「Reactは不要」などと無茶に大きい論点を持ち出し、Reactを否定するのもまた不幸なことだ。
参考文献
JavaScript・Webの歴史
- JavaScript: Designing a Language in 10 Days — IEEE Computer Society。Brendan Eich本人へのインタビュー。JavaScriptが10日間で設計された経緯
- Ajax: A New Approach to Web Applications(PDF) — Jesse James Garrett(2005)。「Ajax」という用語を初めて定義した原典
- Ajax at 20 — Jesse James Garrett自身による20年後の振り返り
- フロントエンドの変遷とReact:なぜ React が主流になったのか — Qiita記事。フロントエンド開発の歴史の概要をまとめている
Flash
- Thoughts on Flash — Wikipedia — Steve Jobsの公開書簡(2010)。AppleがiPhoneでFlashをサポートしない理由を説明した文書
React
- React — Wikipedia — Reactの歴史、Jordan Walkeによる開発経緯
- Hacker Way: Rethinking Web App Development at Facebook(YouTube) — Facebook F8 2014での講演。MVCの問題とFlux(一方向データフロー)の提案。Facebookの通知バッジバグの話もここで語られている
- Facebook: MVC Does Not Scale, Use Flux Instead — InfoQ。上記講演のまとめ記事
- You Might Not Need an Effect — React公式ドキュメント。useEffectの誤用パターンと正しい使い方
React Server Components
- Server Components — React公式ドキュメント
- React Server Components RFC — GitHub。RSCの設計提案書
- Introducing Zero-Bundle-Size React Server Components — React Blog(2020)。RSCの最初の発表
Signals
- TC39 Proposal: Signals — GitHub。JavaScriptの言語標準としてSignalsを導入する提案
htmx・Hotwire
- htmx公式サイト
- Hypermedia Systems — Carson Grossらによる書籍(無料公開)。htmxの思想的背景であるHypermediaアーキテクチャの解説
- Hotwire公式サイト
- Turbo Handbook — Turbo Framesの公式ドキュメント





{kind=link}