
初めまして、フロントエンドコースのRenです。
普段はWILLの運営やフロントエンドコースでカリキュラムチームやレビュワーとして活動しています。ただ、如何せんplaygroundのリアイベにあまり行けていないので、初めましての方が多くなってしまっています…
さて、アドベントカレンダーもいよいよ折り返しに入ってきましたが、本日は「PGritの口コミ分析」というテーマで記事を書きたいと思います。
PGritは、Mastodonをベースに構築されたSNSです。学生や社員が日々の云々を自由に投稿できる場として、Playgroundで活用されています。
本テーマに取り組んだ経緯としては、大学の研究で口コミサイトをスクレイピングしてデータを分析する機会があり、それをきっかけに「PGritでもやってみよう!」という感じです。では、さっそく記事を書いていきたいと思います。
また、私自身がフロントエンドコース出身なので、本記事では主にデータ収集に用いた 「Web スクレイピング」という手法を中心に説明していきます。
1. はじめに
データ分析の大まかな流れは以下のような感じです。
- 対象のデータを取得する。
- データのクレンジングやフィルタリング等を行う。
- データ分析を行う。
- 結果を評価する。
本記事では、主に「1. 口コミ情報を入手する部分」を詳しく説明し、「3. データ分析」の結果を示したいと思います。では、次の章では「1. 対象のデータを取得する」で用いる「Webスクレイピング」について説明したいと思います。
2. Webスクレイピングとは
Webスクレイピングとは、プログラムを用いてウェブサイト上の情報を自動的に収集する手法を指します。この技術を活用することで、口コミサイトやSNSなど、形式的にまとまっていない(ユーザー側から取得できない)有用なデータを効率的に収集することが可能です。
具体的な手法については後述しますが、Webスクレイピングの基本的な考え方として「HTML構造を読み解く」ことが重要です。例えば、(皆さんおなじみ?の)ブラウザの開発者ツールを使用してHTML構造を確認し、取得したいデータがどのタグや要素内に含まれているのかを特定する必要があります。
では、次の章からいよいよ実装していきたいと思います!
注意
Webスクレイピングはデータの収集方法として非常に有用な手法である一方で、サーバーに負荷をかける危険性やサイトによっては規制されている場合がしばしばあります。そのため、対象サイトの規約をしっかりと確認し、必要に応じて許可を得たうえで実施するようにしましょう!
3. 準備
Webスクレイピングおよびデータ分析には以下のツールを使用します。
- Python
- Crhomedriver
- Selenium
軽くツールの説明
Choromedriver
Chromedriverは、Google Chromeブラウザを操作するためのドライバです。Chromeのバージョンに対応したドライバをダウンロードして使用します。私は以下のサイトを参考にしてダウンロードしました。

また、ChoromeDriverの初期設定は以下の様に記述しました。この部分はあまり詳しくないので、詳細についてはぜひ調べてもらえたら助かります。
# ChromeDriverのオプション設定
options = Options()
options.add_argument("--disable-gpu")
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
options.add_argument("--remote-debugging-port=9222")
options.add_argument("--disable-notifications")
# ChromeDriverのパスを指定して初期化
service = Service("pgrit/chromedriver-linux64/chromedriver")
# driver を初期化
driver = None
# ChromeDriverを初期化
driver = webdriver.Chrome(service=service, options=options)Selenium
SeleniumはWebブラウザを自動で操作できるツールです。Pythonなどのプログラミング言語から操作でき、クリックやスクロール、フォームの入力など、手動で行う操作をスクリプトで実行できます。ターミナルからインストールしてください。以下に本分析でも参考にした、Seleniumを使ったデータ収集の記事を貼っておきます。

4. 口コミを取得しよう
では、以下の様な投稿内容を取得していきたいと思います!
はとっちは神!
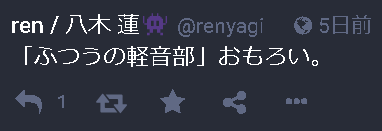
4.1. PGritにログインする
この口コミを取得するにあたって、最初にPGritにログインをしなければなりません。ログイン画面は以下の様な形になっています。
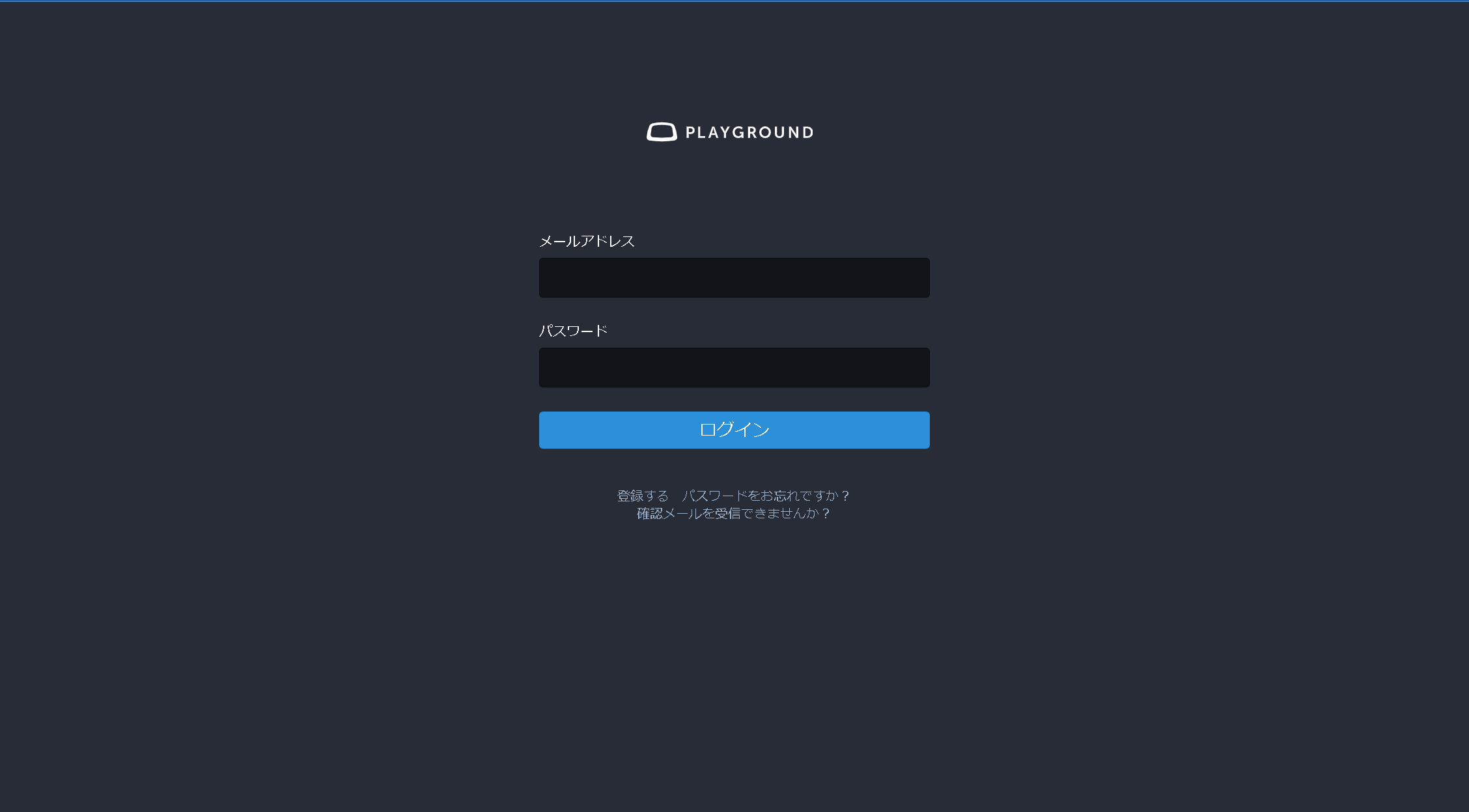
この際、ログインするために必要な操作は以下の様になります。
- メールアドレスを入力する。
- パスワードを入力する。
- フォームを送信する。
これを踏まえて、本画面のHTML構造を確認します。HTML構造の確認には開発者ツールを用いています。
<form ...>
<input ...>
<div class="fields-group">
<div class="input with_label email optional user_email">
<div class="label_input">
<label class="email optional" for="user_email">メールアドレス</label>
<div class="label_input__wrapper"> # メールアドレス欄
<input aria-label="メールアドレス" name="user[email]" ...>
</div>
</div>
</div>
</div>
<div class="fields-group">
<div class="input with_label password optional user_password">
<div class="label_input">
<label class="password optional" for="user_password">パスワード</label>
<div class="label_input__wrapper"> # パスワード欄
<input **aria-label="パスワード" name="user[password]" ...>
</div>
</div>
</div>
</div>
<div class="actions"> # ログインボタン
<button class="btn" ...>ログイン</button>
</div>
</form>すると、メールアドレス欄に入力された値は"user[email]"として、パスワード欄に入力された値は"user[password]"として管理されており、ログインボタンは"btn"というクラス名を持つ buttonタグが対応していることが分かります。したがって、上記のログイン動作は以下の様に言い換えることが出来ます。
- "user[email]"にメールアドレスを埋め込む。
- "user[password]"にパスワードを埋め込む。
- "btn"というクラス名をもつbuttonタグをクリックする。
上記の動作をプログラムに落とし込むと以下の様になります。
# ログインページのURLを指定してブラウザを開く
url_login = "PGritのログインページのURL"
driver.get(url_login)
# メールアドレスの入力フィールドを探し、入力可能になるまで待機
email_input = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.NAME, "user[email]")) # "user[email]" という名前属性を持つ要素を探す
)
# パスワードの入力フィールドを探す
password_input = driver.find_element(By.NAME, "user[password]") # "user[password]" という名前属性を持つ要素を探す
# ユーザー名とパスワードを入力
email_input.send_keys(USER) # USER変数に格納されているメールアドレスを入力
password_input.send_keys(PASSWORD) # PASSWORD変数に格納されているパスワードを入力
# ログインボタンを探してクリックする
submit_button = driver.find_element(By.CSS_SELECTOR, "button.btn") # "button.btn" のCSSセレクタで要素を探す
submit_button.click() # ボタンをクリックしてフォームを送信
# ログイン後のURLが変化するまで待機
WebDriverWait(driver, 10).until(
EC.url_changes(url_login) # URLがログインページのURLから変化するのを待つ
)
# 現在のURLを取得してログインが成功したことを確認
current_url = driver.current_url
print("ログイン成功:", current_url) # ログイン成功後のURLを表示
4.2. 口コミリストを取得する
次に、ログイン後のページにおいて、口コミを取得していきたいと思います。対象の口コミのHTMLを確認します。
<article id="113581574594968514" ...>
<div tabindex="-1">
<div class="status__wrapper status__wrapper-public focusable"
aria-label="ren / 八木 蓮 👾, 「ふつうの軽音部」おもろい。, 12月2日 14:28, renshinonome" ...>
<div class="status status-public" ...>
...
</div>
</div>
</div>
</article>
すると、articleタグ内の"status__wrapper status__wrapper-public focusable"というクラス名を持つdivタグ内の"aria_label"が今回欲しい情報とデータ分析で使えそうな情報を両方持っていました。ちなみに、本articleタグ内のさらに下層のpタグに投稿内容のテキスト情報はありますが、こちらの情報のほうが分かりやすく構造化されているので、今回はこちらの情報を取得します。また、他の投稿も同様に形式/クラス名で統一されている(articleタグの idで管理されている)ため、分析用に一気にとってきます。
上記の動作をプログラムに落とし込むと以下の様になります。
# WebDriverWaitを使って、全ての"article"タグの要素が読み込まれるのを待WebDriverWait(driver, 10).until(
EC.presence_of_all_elements_located((By.TAG_NAME, "article"))
)
# ページ内の全ての"article"タグを取得
articles = driver.find_elements(By.TAG_NAME, "article")
# 抽出したテキストを格納するリスト
extracted_texts = []
# 各articleタグ内のテキストを抽出
for article in articles:
# "status__content__text"クラス名を持つ要素を取得
content = article.find_element(By.CLASS_NAME, "status__content__text")
# "status__wrapper status__wrapper-public focusable"クラス名を持つ要素を取得
content = article.find_element(
By.CSS_SELECTOR, ".status__wrapper.status__wrapper-public.focusable"
)
# aria-label属性から名前と投稿内容、投稿時間を抽出
name = content.get_attribute("aria-label").split(",")[0] # 名前
post_content = content.get_attribute("aria-label").split(",")[1] # 投稿内容
post_time = content.get_attribute("aria-label").split(",")[2] # 投稿時間
# 投稿IDの取得
post_id = article.get_attribute("id") # 記事のIDを仮に取得
# 抽出した情報を辞書形式でリストに追加
extracted_texts.append(
{
"post_id": post_id, # 投稿ID
"name": name, # 投稿者の名前
"post_time": post_time, # 投稿時間
"post_content": post_content, # 投稿内容
}
)5. 口コミ分析
上記プログラムを拡張し、直近(11/22-12/6)500件のの口コミを取得しました。PGritは下にスクロールすると過去の投稿が増える形式となっているので、その部分の実装が大変でした。ちなみに取得したデータの一部はこんな感じです。
[
{
"post_id": "113605544827205995",
"name": "○○",
"post_time": " 12月6日 20:04",
"post_content": " live2dを自動で動かすにはどうすればよいのか"
},
{
"post_id": "113605516970306352",
"name": "○○",
"post_time": " 12月6日 18:11",
"post_content": " #discord_now"
},
{
"post_id": "113604898059647755",
"name": "○○",
"post_time": " 12月6日 17:19",
"post_content": " 推しPが曲非公開にしてた😢"
},
...
}せっかくなので、取得したデータをいくつかの方法で簡単に分析してみました。以下に結果をいくつか示します。
5.1. ワードクラウド
簡単にデータのクレンジング及び単語のフィルタリング(ストップワードの除去、名詞以外の単語の除去)を行い、ワードクラウドを作成しました。結果は以下の様になりました


LTとかGitは「#超LT」の影響が大きそうです。あと、PGritでの活動が多い人は返信とかでアカウント名がよく含まれているのでしょうか。若干、ストップワードに該当しそうな名詞も残っているのですが悪しからず。
5.2. 感情分析
投稿ごとに感情分析(投稿内容のポジティブ度の数値化)を行い、投稿内容をpositive、negative、neautralの3つに分類しました。使用したモデルは、私自身の研究で口コミ分析をした際に他モデルと比べて高い精度を示した事前学習済みの BERT ベースのモデルである
"LoneWolfgang/bert-for-japanese-twitter-sentiment"です。本分析では、他モデルとの比較や精度の評価などは行っていないので、一つの参考結果として見ていただけるとありがたいです。
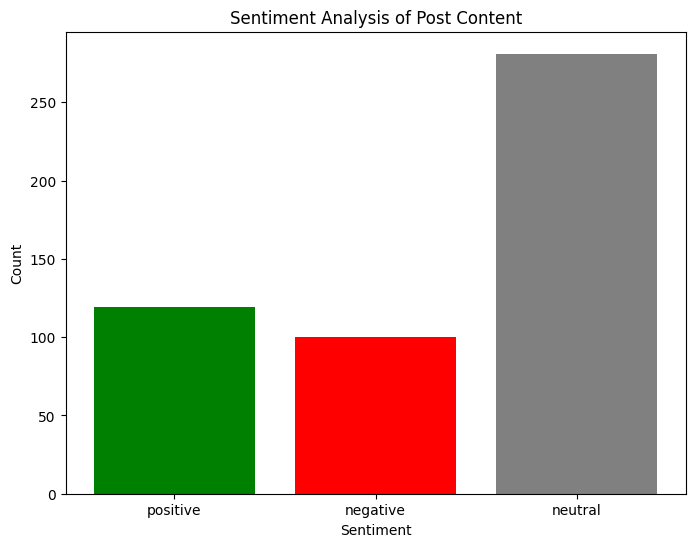
neutralが多いのは予想通りでしたが、最近はpositiveな投稿がnegativeな投稿より若干多いみたいです。安心ですね。
6. 終わりに
ここまでお読みいただいた方々、ありがとうございました。Webスクレイピング自体は主にデータサイエンスの領域で用いる手法ですが、その手法を上手く扱うには「HTML構造を読み解く」というフロントエンドの強みが必要となります。そのため、コースの壁に囚われずに様々な分野に触れるとなんだかんだで今まで学んだことが活きる機会も多いのかもしれませんね。
アドベントカレンダーの後半戦初日となる明日はRisaさんです。よろしくお願いします!






{kind=link}