
こんばんは。PlayGround Advent Calender 2024 の 12 日目を担当する yuji です。
PlayGround ではデータコースに所属していて、大学では自然言語処理の研究をしています。
最近、他大の研究室の輪読会に混ざらせていただいて、情報幾何に入門しています。勉強のモチベを維持するために、情報幾何が深層学習の理論研究においてどのように役立っているのかを知っておきたくなり次の論文を読みました。
Information Geometry of Evolution of Neural Network Parameters While Training
Abhiram Anand Thiruthummal, Eun-jin Kim, Sergiy Shelyag
Neurocomputing journal 2024
https://arxiv.org/abs/2406.05295
本記事では、前半で自分と情報幾何との接点を、後半でこの論文の紹介を書きます。解説というより感想です。
yuji と情報幾何との接点
まず最初に「情報幾何とは〜」という導入をしたいのですが、なにぶん入門者過ぎて簡単に説明できるほど理解できていません。こちらの note によると「確率分布たちの集合に幾何構造を入れてその性質を調べる分野」と端的に言えるそうです。もっと簡単には、2 つの確率分布 f, g がどれだけ近いかを測る道具を作っているとも言えるかもしれません。
ぶっちゃけると、自分は間違って情報幾何学に入門したかもしれません。
というのも、勉強を進めるにつれて、自分の興味を満たすだけなら「情報」「幾何学」ではなく多様体を扱う「幾何学」までで十分かもしれないと気づき始めたからです。まあ JavaScript の勉強をしていたつもりが間違えて TypeScript の勉強をしてしまったように、無駄ではなくむしろラッキーだと思い込むことにします。
というわけで、見出しとは変わりますが、yuji が多様体のどんなところに興味を抱いているのかを具体例に触れつつ紹介します。
Q. 下図において、点 B, A 間の距離と点 B, C 間の距離はどちらの方が近いでしょうか?(どちらの方が近いと思いたいですか?)
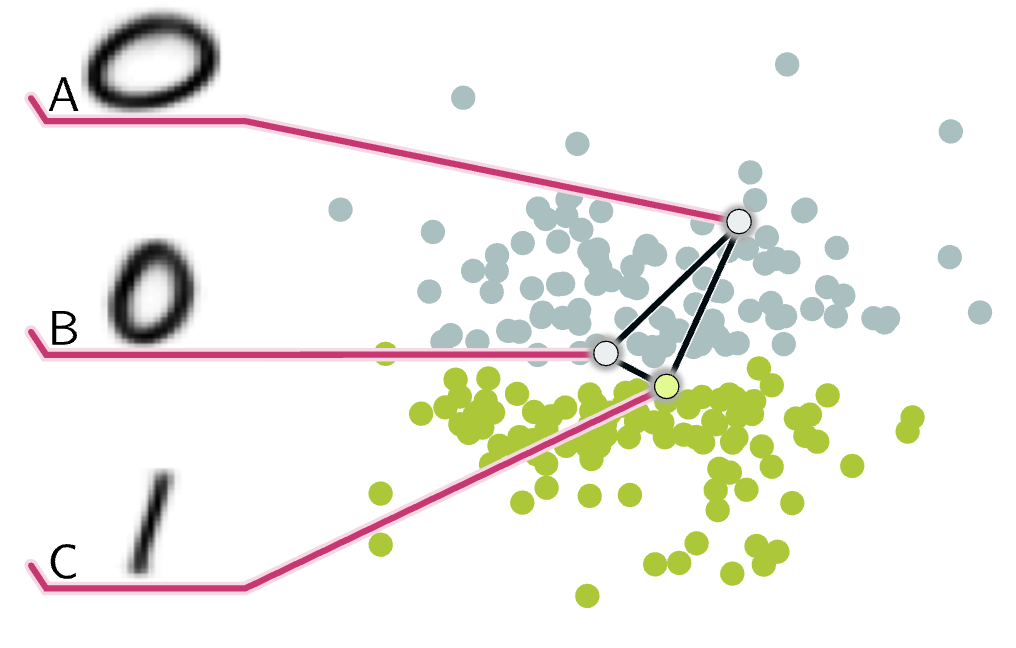
(Arvanitidis et al. 2017) の図 1 を引用。
通常の距離(ユークリッド距離)で測ると、点 B は、点 C とは近いですが点 A からは離れています。しかし、データの性質を考慮すると、逆の方が自然です。
ここで、上図の空間は歪んでいて、点 B と点 C の間には深い谷があるとします。すると、点 B から点 C にたどり着くためには長い経路をたどらなければならないが、点 B から点 A へはフラットな経路を少したどるだけで良いことになります。多様体論ではこのように歪んだ空間を扱います。
データ同士を比較するときに距離を使うというのはごく自然な操作です。しかし、実世界のデータが実は歪んだ空間上に分布していた場合、この操作は不自然な結果をもたらすかもしれません。そこで yuji はデータの本質を知るために空間の歪みも考慮する多様体に興味を持ちました。
論文紹介:Information Geometry of Evolution of Neural Network Parameters While Training
短い要約
情報幾何の指標を用いると、テストデータを使うことなくモデルのみから過学習のタイミングが分かりそうという話。
イントロ:ニューラルネットワークを情報幾何で分析する
論文のタイトルを和訳すると「学習中のニューラルネットワークのパラメータの進化に対する情報幾何」となります(以後、ニューラルネットワークは NN と略記)。NN のパラメータは学習前に乱数で初期化されます。それが少しずつ与えられる学習データのもとでパラメータを更新するステップを何度も繰り返すことで最適なパラメータへと進化していきます。
ここで、NN のパラメータの確率分布を考えます。すると、「確率分布たちの集合に幾何構造を入れてその性質を調べる分野」である情報幾何のツールを使って学習中の NN 同士を比較することでそれらの性質を調べることができます。
「NN のパラメータの分布って何?」と感じた方だけに向けて雑に自分の理解を書きます。ことばで説明するのを諦めてコードにしていますが、次のようなものです。
NN: nn.Module
params = concat([param.flatten() for param in NN.parameters()])
plt.hist(params)
つまり、本当に文字通り NN のパラメータの分布です(多分)。私はベイジアンネットワークの雑念があったせいで、パラメータの不確かさのことかと勘違いして躓きました。
準備:情報距離の定義
情報幾何(に限らず統計学や情報理論)にはフィッシャー情報量という統計量があります。この論文で用いられているシンプル化された定義は次の通りです。
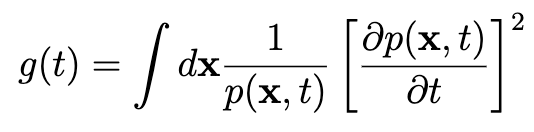
ここで現れる p(x, t) が学習ステップ t における NN のパラメータの分布です。
さて、フィッシャー情報量とは、どんな意味を持つ量であり、これを使うとどんな分析ができるのでしょうか。分かりません。それを知るために、実際にフィッシャー情報量に基づいて分析しているこの論文を読んでいます。
論文では、さらに情報距離(Information length)という指標を導入しています。
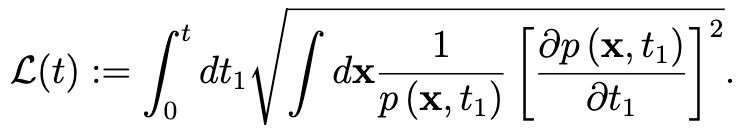
これは、フィッシャー情報量の平方根をとり学習ステップについて 0~t で積分しています。
§4.2. ドロップアウト正則化と情報距離
論文の中身を全部書くのは大変なので、特に面白いと感じたセクションを選んで紹介します。
ドロップアウト正則化とは最近のほぼ全ての深層学習モデルで採用されている、過学習を抑制する手法です。学習中に 0 ≦ p ≦ 1 の確率でニューロンを無効化することで、一部のニューロンが過度に学習することを避けます。
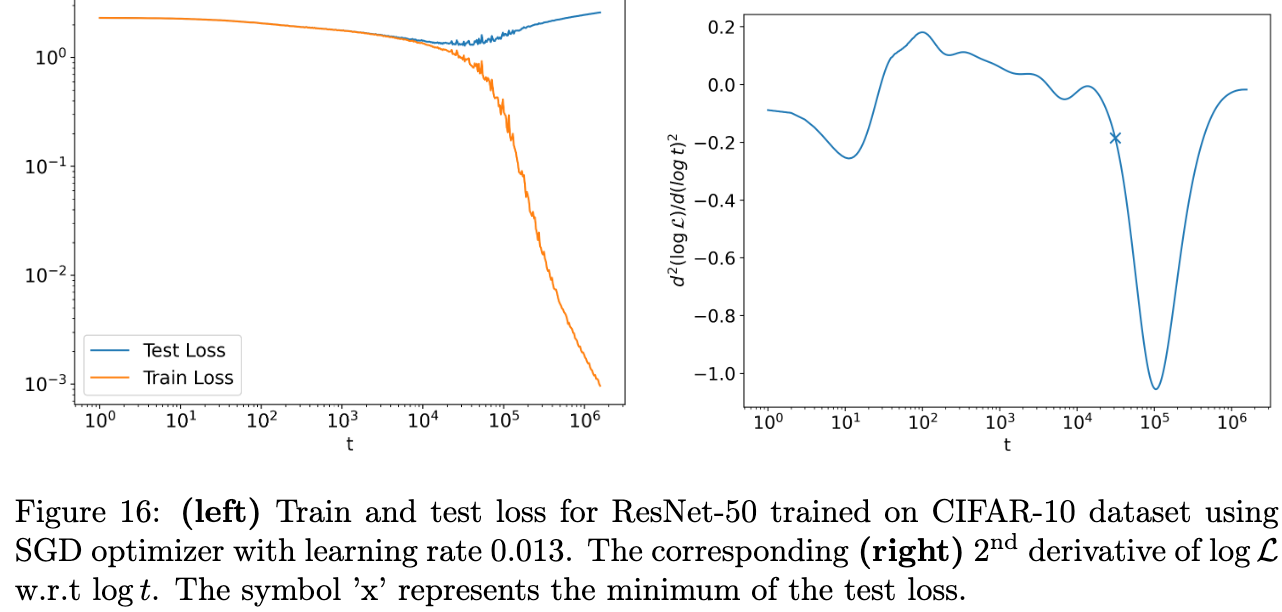
ドロップアウト確率 p を色々変えて NN を学習させてみると、p が高い方がテストデータに対する loss が小さく、過学習が遅れて始まっていることが分かります。つまり、ドロップアウト確率 p が高い方が過学習を抑制できています。
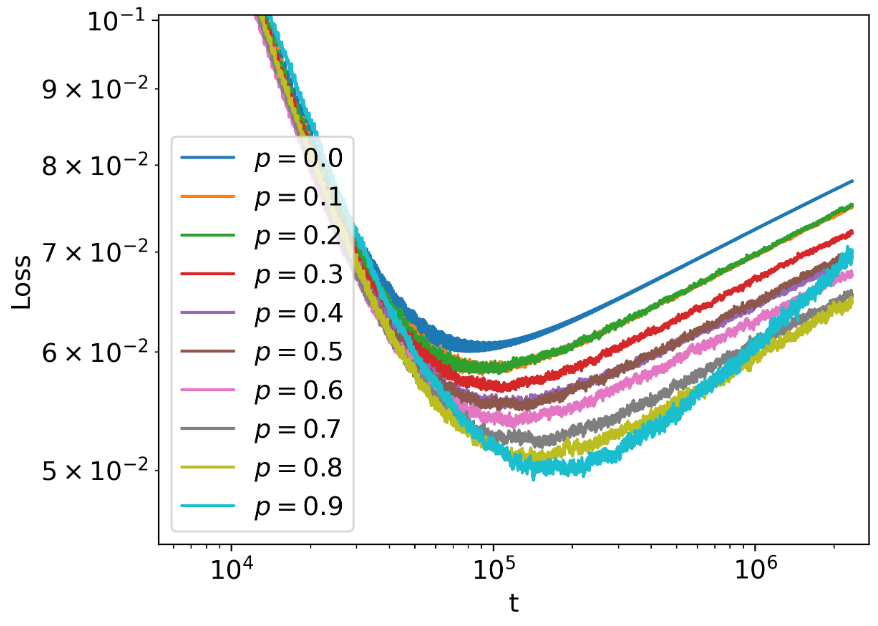
論文の図 10 左を引用。
このときの NN のパラメータがどのように進化しているかを情報距離 L というレンズで覗いてみます。ただし、注目したいポイントが強調されるように、情報距離 L を次のように加工します。
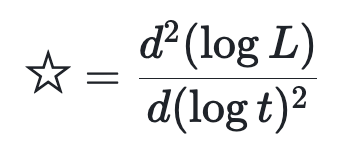
この値を学習ステップ t についてプロットすると下図になります。t=10^5 あたりにあるバツ印は過学習が始まったときの学習ステップです。
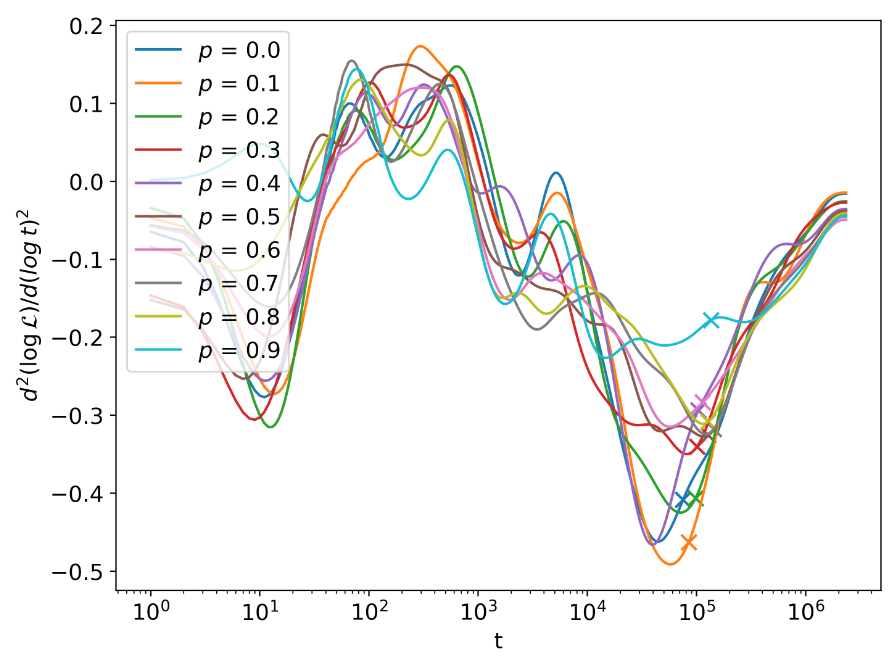
論文の図 11 左を引用。
過学習が始まったバツ印の周辺を見ると、ドロップアウト確率 p が小さいほど ☆ の値が急落する傾向があります。つまり、☆ の値の下がり方がより急であるほどより深刻な過学習が始まる関係であることが示唆されます。ここでポイントなのが ☆ の計算にはテストデータを用いていないことです。つまり、(フィッシャー情報量に基づく)情報距離というレンズで学習中の NN のパラメータの変化を追えば、モデルが壊れたことを察することができるのかもしれません。
余談ですが、☆ が役立ちそうということは分かったとして、☆ の値の大小に解釈を与えることってできるんですかね。情報距離を 2 階微分したような形だから加速度のように解釈しても許されそう:過学習が起きるとパラメータの更新に急にブレーキが掛かってすぐにそれが緩むみたいに。
あとがき
過学習前の良質なモデルと過学習後の悪質なモデルでは明らかに振る舞いが異なります。しかし、プログラム上ではこれらは膨大な数の float のかたまりという点では全く同じに見えます。この違いが情報幾何的視点では捉えられるというのが興味深く感じました。
「ぶっちゃけると、自分は間違って情報幾何学に入門したかもしれません」とは言いましたが、ふらっと立ち寄った店が良い雰囲気だったので常連になっちゃおうみたいな感じでのめり込んじゃうかもしれません。
さて、Advent Calendar 2024 は前半が終了し、明日 (13日目) の Ren くんの記事で折り返しを迎えます。コミュニティ内の SNS を題材にテキスト分析するという、自分の専門・興味にストライクな内容なので楽しみです。それではまた明日👋





{kind=link}