![[データサイエンス]データ分析で何すればいいの?](/content/images/size/w1200/2023/12/samune-data.png)
始めに
自己紹介
この記事は、PlayGround Advent Calendar 2023の23日目担当分です。
皆さん、初めまして!鬼頭勇輝と申します。きとポンいうニックネームでデータサイエンスコースの修了生としてデータ分析の活動をしています!データサイエンスの分析手法について統計学も含めた適切なアプローチはないか日々勉強しながらデータ分析の精度を上げようと頑張っています!記事を書くのは今回が初めてなので、分かりにくい箇所があったらすみません!
この記事を見に来てくださり、ありがとうございます!この記事をご覧になって1人でも多くの方がデータ分析について関心を持って下さったら幸いです!
このテーマにした理由
このテーマにした理由として、データ分析の基本的な流れを紹介することで、
1.効率よくデータ分析の全体像を把握できる。
2.各自でモデルの改善を効率よく行える。
と考えたからです。
データ分析の前処理などのやり方について、基本的な流れを明示しているサイトが私の認識している限り、少ないと思いました。今回、データ分析についての一通りの流れを掲載することで、素早くデータ分析の分析スキルを向上させたい方に貢献できるのではないかなと考えました。
目次
- データ分析の予測するものの種類
- コンペの基本的なデータ分析の流れ
- データ分析の決定木系列の機械学習モデルでの注意すること
- データ分析の回帰式系列の機械学習モデルでの注意すること
- どのようにモデルを改善していくか
- 余談(データ分析前の工程について)
1.データ分析の予測するもの種類
データ分析の予測する項目は以下の2種類があります。
- 分類型(「晴れか、雨か、曇りか」、「生きるか、死ぬか」などの選択問題の形式)
- 回帰型(「売上額はどれくらいか」などの連続した値の形式)
基本的にこの2つの形式の問題に対して、予測モデルを作ります。
2.基本的なデータ分析の流れ
前提のお話
最初に、今回扱うcsvファイルのデータの形式は読者自身で検索して確かめて下さい。
※データの所有権の関係上、csvファイルの例をお見せできないため、KaggleやSignateの訓練データなどを参考にしてみて下さい。
数値データとしてcsvファイル形式、excelファイル形式で、受け取ります。
本題
コンペにおいて、データ分析を行うには以下の手順を踏むことが望ましいです。
課題の把握
↓
評価関数の設定
↓
目標の設定
↓
データの可視化での把握
↓
仮説の設定(前処理とか機械学習モデルに見当をつける)
↓
前処理
↓
機械学習モデル
↓
評価
↓
考察
↓
仮説の立て直し
この流れを繰り返していきます。詳細の説明を下に示しておきます。
2-0. 課題の把握
まずは、何のデータを分析して何の予測を行うのかを理解することが重要だと思っています。また、なぜ、このデータの列があるのかということも考えることが大切です。
2-1. 評価関数の設定
評価関数についてですが、分類型と回帰型でどのような評価関数があるかまとめておきます。ただ、各課題ごとに適切な評価関数は違うので、「何を予測しようとしているのか」と「評価関数のメリット・デメリット」の2つを考慮して評価関数を決定する必要があります。
1.分類型
〇正解率
〇再現率
〇適合率
〇f1-score
など
2.回帰型
〇MAE(平均絶対誤差)
〇MSE(平均二乗誤差)
〇RMSE(平均二乗平方根誤差)
〇RMSLE(平均二乗対数平方根誤差)
など
2-2.目標の設定
KaggleやSignateで挑戦する際は、リーダーボードで確認して目標を設定します。上位何%を目指すかで目標は変わってきます。
評価方法はKaggleであれば、「概要」の「評価方法」を見るとわかります。
コンペ以外でのプロジェクトでは、どの精度までを目指すかは様々な視点から判断する必要があります。
2-3.データの可視化
データの可視化は、データをグラフ化することであり、データを理解するために行われます。
次の3項目をグラフ化して考えるとよいと思います。
1.目的変数と説明変数の関係性
2.データの外れ値があるか見当をつける
3.個々の説明変数のデータの分布を理解する
これをmatplotlibやpandasやBIツールなどで行うことで、前処理をどうしていくのかを決定する事ができます。
2-4.仮説の設定
どう前処理をするか、どう機械学習モデルを使えばうまく行くのかの仮説をデータの可視化(データのグラフ化)に基づいてここで立てます。その時にどういう風に処理するかモデルの設計図を作成するといいと思います。
2-5.前処理
データの前処理は様々な前処理から選んでいきます。前処理の代表例を下記にあげます。各説明と使い方やこの前処理の意味は割愛します。ここを使いこなせるかがデータ分析の肝になるのではないかなと思います。
- 特徴量選択(AzureMLというクラウドなどで可能です、ラッパ法など)
- 特徴量抽出(主成分分析:PCA)
- データをグループ化(K-Means法)
- 標準化(平均0,分散1のスケールにする)
- 欠損値処理(線形補間や機械学習による補間、中央値での補間など)
- 外れ値処理(マハラノビス距離、robust Z-scoreなど)
- ダミー変数化(one-hot encoding, label encoding, target encoding など)
- 非線形変換(ログ変換、平方根変換、Cox-Box変換、Yeo-Johnson変換など)
- 特徴量エンジニアリング(新しい特徴量を作る(多項式特徴量、交互作用特徴量))
- ビニング
- データクレンジング(誤字脱字の修正、一貫性のないデータの統一、不適切なデータの修正)
2-6.機械学習モデル
機械学習モデルは回帰問題のもの、分類問題のもの、どちらも使えるものがあります。
回帰問題
- 重回帰
- Ridge回帰
- Lasso回帰
全てのアプローチでそれぞれのデータの分散が最小となる直線を求めていますが、2と3で制限が設けられています。(下記の図は横軸が説明変数、縦軸を目的変数としています。便宜上、説明変数1つに対して、目的変数を予測する回帰直線をモデルにしています。)
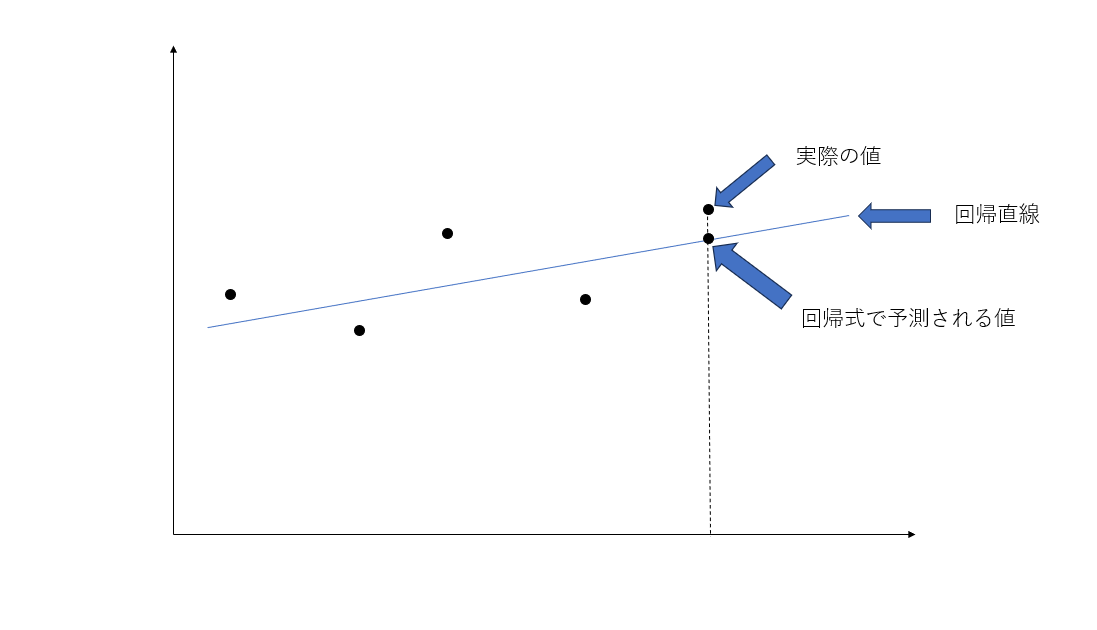
重回帰はかなりの確率で過学習を起こす可能性が高いです。
過学習というのは、訓練データの細部まで学習してしまって未知のデータの予測に悪影響が出ることを言います。この状況を抑えるために、回帰式(直線)の傾きに制限を加えたり、説明変数を減らしたりしています。前者がリッジ回帰で、後者がラッソ回帰となります。
分類問題
- ロジスティック回帰
ロジッスティック回帰では重回帰分析の分類問題バージョンです。各クラスの確率を求めてくれます。確率の高いクラスを分類結果に表示します。過学習は起こしやすいです。
どちらでも
- 決定木
- ランダムフォーレスト
- 勾配ブースティング決定木
決定木は以下のようにして分類を行うものを言います。
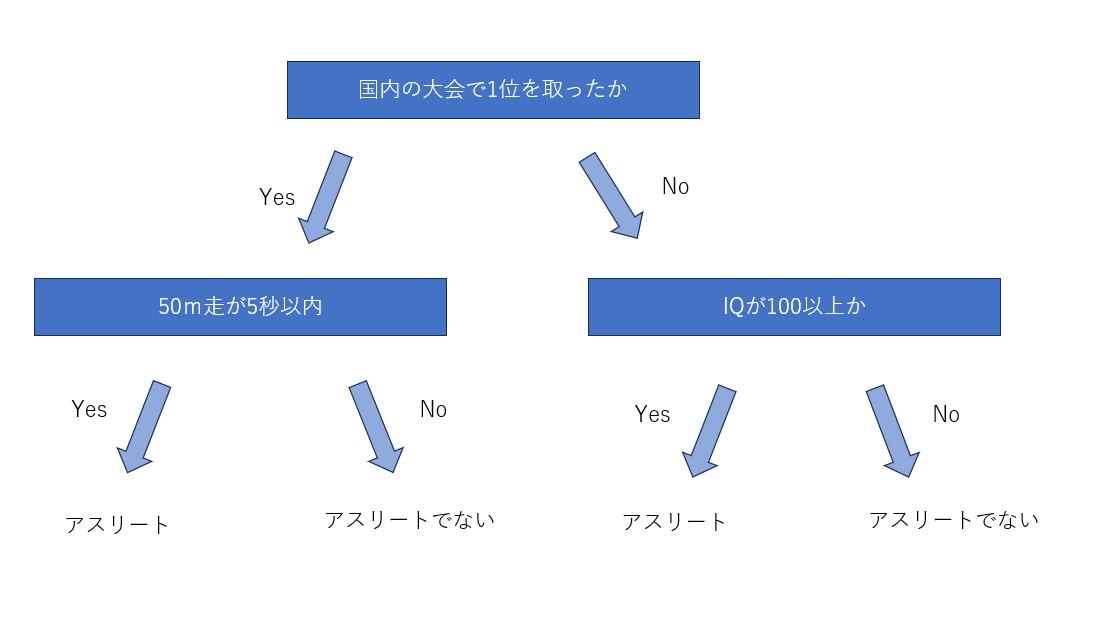
しかし、決定木はアルゴリズムが単純であるため、精度が低いです。比較として、重回帰よりも低いこともあります。ここで、決定木の結果を利用して精度を上げた機械学習モデルがランダムフォーレストや勾配ブースティングです。
ランダムフォーレストは、沢山の決定木を用意して多数決で決めます。過学習も起こしにくく、かなり精度は高いです。
一方で、勾配ブースティングは、沢山の決定木を用意してそれらを直列にして以前の決定木の誤った情報や結果を次の決定木がもらってそれを使ってより精度の高いモデルを構築します。過学習を起こしやすいので、機械学習モデルのパラメータをいくつかの手法で丁寧に調整する必要があります。しかし、それを克服すれば、精度の威力はランダムフォーレストを上回る傾向にあります。
2-7.評価して考察
その後、評価関数を使って評価します。その際に、クロスバリエーションを作ることが精度を上げるコツです。以下がクロスバリエーションの図です。(今回はデータを5分割しています。)

データの種類には、訓練データと検証用データやテストデータがあって、訓練データは機械学習するためのデータで、検証用データは精度を向上するためのよく使うデータ、テストデータは未知のデータにも精度がしっかり担保されている確認するデータとなります。クロスバリエーションでは、訓練データ&検証用データを分割して各1つのセクションで検証用データの時の訓練データと検証用データの精度を出して行きます。検証用データの平均値がチェックする精度になります。
この精度で、次どうするか決めて行きます。
3.決定木系列の機械学習モデルで注意すること
決定木系列の機械学習モデルは、具体的に言うと、決定木やランダムフォーレストや勾配ブースティング決定木を指しています。ランダムフォーレストや勾配ブースティング決定木では、決定木に基づく、機械学習モデルです。
これらのモデルに共通して言えることは、
- 欠損値処理や外れ値処理の処理はある程度強い。
- Cox-Box変換のような非線形変換の必ず使う必要はない。
- 正規化や標準化はしなくてよい。
- ダミー変数はone-targetでも良い。
といった特色があります。
4.回帰式系列の機械学習モデルで注意すること
回帰式系列の機械学習モデルはロジスティック回帰、重回帰、Ridge回帰、Lasso回帰を指しています。このような線形モデルでは共通して以下のようなことが言えます。
- 欠損値処理は必須
- 外れ値処理は必須
- 標準化は必須
- ダミー変数化必須(one-hot-encodingおすすめ)
- 多重線形性は考える必要あり
- 非線形変換(ログ変換、平方根変換、Cox-Box変換、Yeo-Johnson変換)おすすめ
多重線形性などの話は割愛しますが、色々な前処理をして精度を上げていくとよいです。
5.どのようにモデルを改善していくか
最終的には、データの可視化からこういう前処理だとうまくいくのではないかと仮説を立てて精度を上げていく。あるいは、ハイパーパラメータ調節をして精度を上げていくと思いますが、基本的には前処理を重視して行っていくと、精度が上がっていきます。なので、前処理を当面の間は改善していって精度が頭打ちになったら、ハイパーパラメータに目を向けるとよいと思います。それでも、うまく精度が上がらなければ、機械学習アルゴリズムを変える方がいいと思います。
流れとして、
勾配ブースティング→ニューラルネットワーク、線形モデル→ ランダムフォーレストなど
の順番が良いと言われています。
6.余談(データ分析前の作業について)
今回は、KaggleやSignateを想定してお話しましたが、データ分析を一から作ろうとしたときに気づいたことがあったので、最後にお伝えしたいと思います!
大学のプロジェクトなどでわかったことなのですが、データを分析する前に
- 今回の課題の確認。目的を確認。
- 何がその問題に影響を及ぼすか、専門家と議論する。
- どのデータを持ってくるか決める。(その時に専門家の人などの意見を用いてどの変数のデータを集めていくか決める。)
- そのデータを会社のデータベースから取り出したり、自分でデータを作ったりする。
このような形でデータ分析する前のcsvファイルとしてデータが出来上がっているのだと思います。
ここは、あくまでも参考でお願いします。また、詳しく勉強して次の記事で取り上げると思います。
まとめ
前処理や機械学習アルゴリズムを知ったうえで、
- データ分析の流れを知る
- 回帰式系統及び決定木系統のアルゴリズムの前処理における特徴を知っておく
これを知っておくだけでも、データ分析の精度を効率よく上げることが可能です!ぜひ、私と一緒にデータ分析、頑張っていきましょう!




{kind=link}