
みなさんこんにちは!今年もやって参りましたAdventCalendar2024のトップバッターTatsuroです。
「ガキども俺に続け!」というわけで、今回はハッカソンでやらかした話をしようと思います。
クラウド破産。怖いですよね、、
Tokyo Flutter Hackathon
僕は11/2,3にAbema Towersで開催された Tokyo Flutter Hackathonに参加してきました。
4人チーム(デザイナー1,フロント2,バックエンド1)で僕はバックエンド・インフラを担当しました。
ということで、今回はハッカソンでのバックエンド・インフラ実装についてお話しします。
(後日他のメンバーのAdventCalendarでデザイン・フロントの話があるかも?)



実装
ハッカソンのテーマが「HOT」ということで、「HOT」→「熱い」→「辛い」??のように連想しました。また、Flutterといえばあの青い鳥が思い浮かんだので、DASHを使ったアプリを開発しようという結論に至りました。
というわけで、開発したアプリがこちら↓↓↓
 shinonome-inc
shinonome-inc

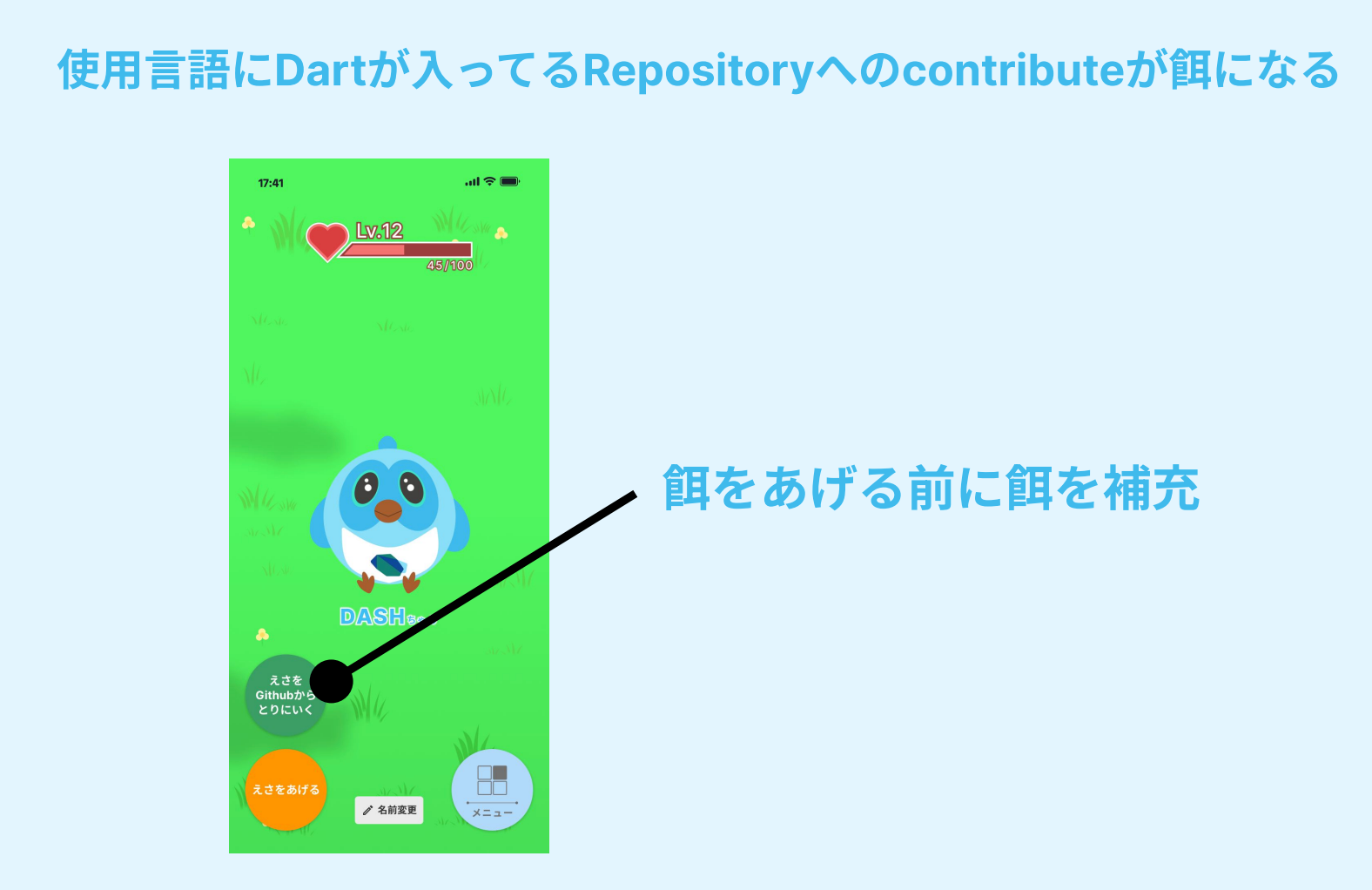
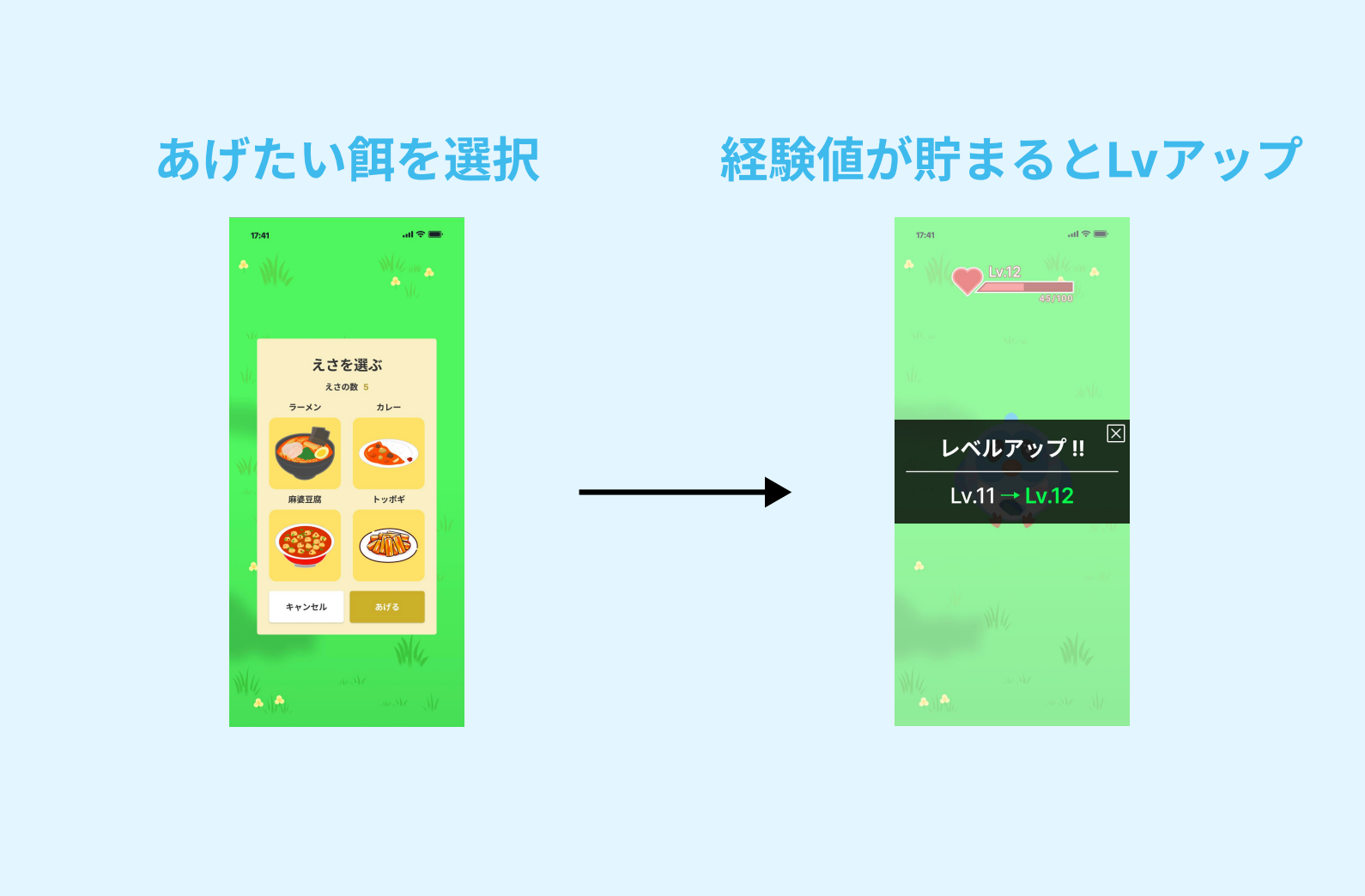
簡単にアプリの説明をすると、GitHubのリポジトリ(使用言語にDartが含まれる)へのコントリビュートを取得して、Dashに餌をあげることができる仕様になっています。餌をあげると経験値が貯まってレベルアップ、背景の変更や着せ替えもできます(デザイナー様々)。
アーキテクチャ
以下のアーキテクチャで実装しました。バックエンド・インフラ側の実装です、Flutterは認証部分以外自分で書いてないのであんまわかりません(Flutterハッカソンなのに...)。
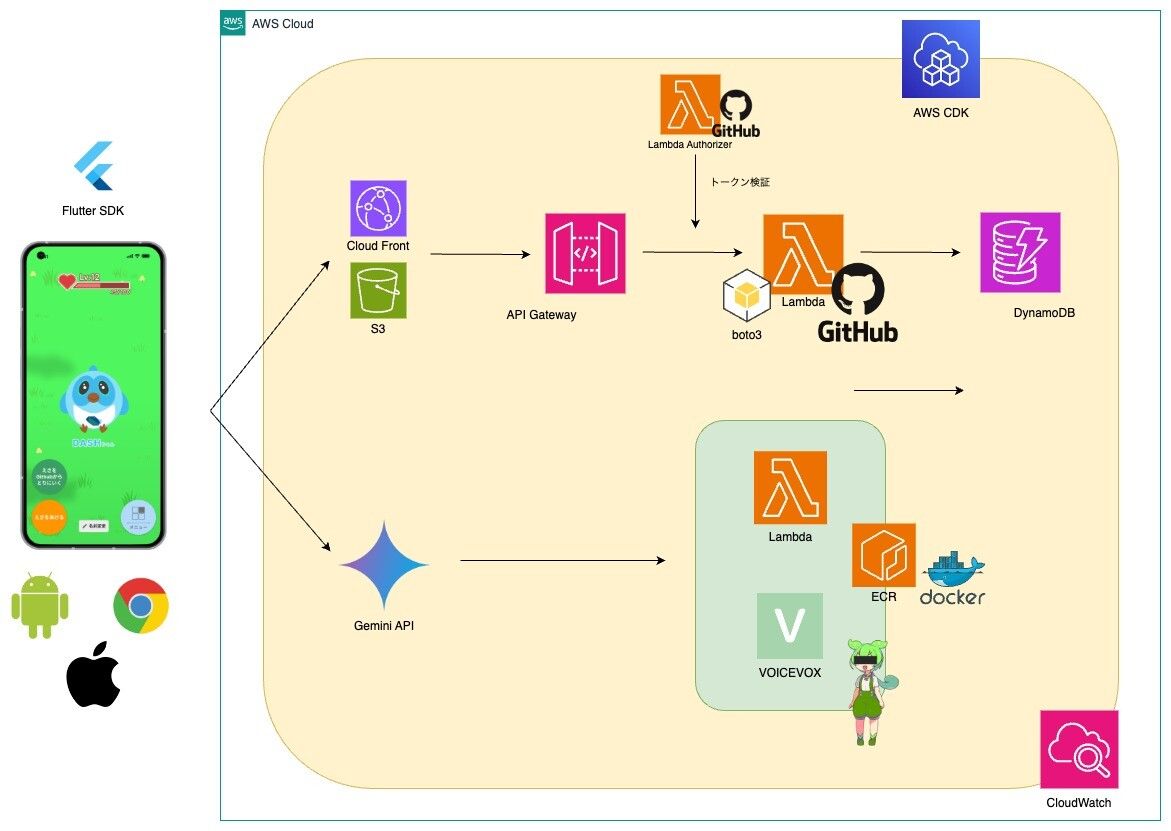
こだわりポイント
1. AWS CDKでIaC化
言うまでもないっすね。サーバレス構成ってマネコンぽちぽちでも出来ますが、再現性も保守性もないしダサいっすよね。terraform, cdk使いましょう。
2. GraphQLでGitHub APIにリクエスト
GitHubのAPIってリクエスト制限かかりやすいんでGraphQL verのAPIでオーバーフェッチ避けないとですよね?ということでqueryを作ってリクエストしてます。
// lambda/utils/get_feed.py
query = """
query($login: String!, $from: DateTime!, $to: DateTime!) {
user(login: $login) {
contributionsCollection(from: $from, to: $to) {
commitContributionsByRepository(maxRepositories: 100) {
repository {
name
languages(first: 10) {
nodes {
name
}
}
}
contributions {
totalCount
}
}
issueContributionsByRepository(maxRepositories: 100) {
repository {
name
languages(first: 10) {
nodes {
name
}
}
}
contributions {
totalCount
}
}
pullRequestContributionsByRepository(maxRepositories: 100) {
repository {
name
languages(first: 10) {
nodes {
name
}
}
}
contributions {
totalCount
}
}
}
}
}
for contribution_type in ['commitContributionsByRepository', 'issueContributionsByRepository', 'pullRequestContributionsByRepository']:
dart_contributions += sum(
repo['contributions']['totalCount']
for repo in response_data['data']['user']['contributionsCollection'][contribution_type]
if any(lang['name'] == 'Dart' for lang in repo['repository']['languages']['nodes'])
)
* 餌が「Dartが使用言語に含まれるリポジトリへのコントリビュート」なので、雑に絞り込んでます。
3. Lambda Authorizer使ってみた
アーキテクチャ図の参照の通り、API Gatewayにリクエストが飛んできた場合、誰でも彼でもLambdaを動かせちゃマズいわけです。そこで、逐次GitHubにアクセストークンが正しいかどうか確認するリクエストを投げてます。問題なければ「LambdaをInvokeするポリシー」をAPIGatewayに渡してあげます。
// lambda/auth/authorizer.py
def generate_policy(principal_id, effect, resource, context=None):
"""IAMポリシーを生成"""
auth_response = {
'principalId': principal_id
}
if effect and resource:
auth_response['policyDocument'] = {
'Version': '2012-10-17',
'Statement': [
{
'Action': 'execute-api:Invoke',
'Effect': effect,
'Resource': resource
}
]
}
if context:
auth_response['context'] = context
return auth_response
4. VOICEVOXのイメージをLambdaで動かす
Dashを喋らせるために、ubuntuのDockerイメージをECRにプッシュしてLambdaで動かす構成にしてます。
あとはFlutter側で受け取ったエンコードされているmp3ファイルをデコードすればいいだけです。
(が、今はバグってて喋りません。)
SPEAKER_ID = 1 // ずんだもんボイス
core = VoicevoxCore(
acceleration_mode=AccelerationMode.AUTO,
open_jtalk_dict_dir=os.environ["OPEN_JTALK_DICT_DIR"],
)
core.load_model(SPEAKER_ID)
def lambda_handler(event, context):
print(event)
body = base64.b64decode(event["body"]).decode("utf-8")
query = parse.parse_qs(body)
texts = query.get("text")
if not texts or len(texts) == 0:
return {
"statusCode": 422,
"header": ,
"body": "Text not provided",
}
text = texts[0]
print(f"text: {text}")
mp3 = wav_to_mp3(get_voice(text))
return {
"statusCode": 200,
"header": ,
"body": base64.b64encode(mp3).decode('utf-8'),
"isBase64Encoded": True,
}
def get_voice(text: str) -> bytes:
audio_query = core.audio_query(text, SPEAKER_ID)
return core.synthesis(audio_query, SPEAKER_ID)
def wav_to_mp3(wav: bytes) -> bytes:
with NamedTemporaryFile() as f:
AudioSegment.from_wav(io.BytesIO(wav)).export(f.name, format="mp3")
return f.read()
5. Provisioned Concurrencyでlambdaをウォームスタート ← こいつが本題
はい、お待たせしました。長くなりましたがこいつが本題です。
僕が何をしたかったかというと(端的に)、ハッカソンのデモで良い感じに遅延なく見せたかったわけです。
特に、音声機能なんかはレスポンスに時間がかかります(Geminiで文章生成 → VOICEVOXに投げる)。
そこで、Lambdaのメモリを爆増かつウォームスタートに設定すれば速くなるのでは??と期待した訳です。
もう少し詳しく説明しましょう。
Lambdaというのはそもそもコールドスタートなんです。
最初にリクエストが来た瞬間に実行環境が用意されてLambdaが動くわけです。この起動プロセスは初回または長時間アイドル状態の後に関数が呼び出されるときに行われます。この起動にかかる時間が実はネックで、結構時間かかったりします。
このウォームスタートを設定するのがProvisioned Concurrency(準備された同時実行)というものです。あらかじめ台数を指定してウォームスタートで実行できます。
また今回の料金請求にあんまり関係ないですが、メモリサイズを増やすことでLambda実行環境のCPUパワーや、帯域が向上します。こういった背景がありました。
メモリ3008MB、100台固定で予約(AutoScaling設定できるの知らなかった)。
請求結果

速くなりました。そして飛んできた請求がこちら↓↓↓

実行時間にして12時間、13000円の請求が飛んできました。ハハ🐭
まとめ
お分かり頂けただろうか?
ちゃんと料金計算しましょう。「12時間だけだし多分大丈夫っしょ!!」で痛い目を見ました。
恐ろしいのが、ハッカソンの懇親会でいろんな人から「どのくらいの期間サービス公開してるの?」と聞かれて適当に「まあ1ヶ月くらいすかねー」とか言ってましたが、次の日になんとなく請求確認して止めてなかったらやばかったですね。
数十万の請求が飛んできていたことは想像に難くない(まあCost Anomaly Detectionで怪しいメール飛んできてたけど。)
ちなみにハッカソンの結果はというと、大満足です!スポンサー賞を頂けました😎
株式会社YUMEMIのよーたんさんから「ゆめみ賞」として「お願い事を1つ叶えてもらえる券」を頂きました。
使い道はまだ秘密です!

僕は写真右上。以下、公式ツイート。
明日12/2のAdventCalendar担当はRyomaです!
優秀なデータサイエンティストである彼なら、
さぞ素晴らしいテックブログを書き上げてくれることでしょう!!
改めて、12/25までのAdventCalendar2024をお楽しみに!!





{kind=link}