
メリークリスマス。データサイエンスコースの山本です。振り返りも兼ねてオンラインオフィス DAWN の 2022 年の入退室ログを使ってコミュニティ分析をしてみました。
データ整形
前処理の話をすると長くなってしまうので簡単に。
表 1 のような形式の入退室ログから「A さんと B さんは 55 分間同じ部屋にいた」というのを見つけて、表 2 のような行列に変換するということをしました。
表 1 : アクセスログ
| 日時 | ユーザ | 部屋 | フラグ |
|---|---|---|---|
| 2022-01-01 12:00 | A | プロジェクト MTG | 入室 |
| 2022-01-01 12:05 | B | プロジェクト MTG | 入室 |
| 2022-01-01 13:00 | A | プロジェクト MTG | 退室 |
| ... |
表 2 : 隣接行列
| A | B | ... | |
|---|---|---|---|
| A | 0 | 55 min | |
| B | 55 min | 0 | |
| ... |
表 2 の形式は 隣接行列 (adjacency matrix) といってネットワークグラフを表現する時によく使われます。
この処理は for 文でひたすら 1 行ずつ回して同じ部屋にいた人と時間を記録するという多分 O(N) の実装をしているのですが、SQL でできたら Grafana とかにも組み込めるらしいので理想的なんですよね…。でも、"同じ部屋にいた" っていうのを捉えるのはやっぱりむずいのかな。
以降はこの行列の各成分を累計時間に変換して hours_mat (pd.DataFrame) と呼ぶことにします。
可視化
とりあえずデータが集まったら可視化してみたいですよね。ってことでグラフを作ってみましょう。
可視化ライブラリには色々種類があるのですが、とりあえず見た目にはこだわらないので matplotlib を使うことにします。
| ライブラリ | サンプルコード | 使った感想 |
|---|---|---|
| plotly | link | コードが汚くなりがち |
| bokeh | link | 使ったこと無い |
| pyvis | link | matplotlib < pyvis < plotly |
| matplotlib | link | 実家のような安心感 |
import matplotlib.pyplot as plt
import networkx as nx
G = nx.from_numpy_array(hours_mat.to_numpy())
pos = nx.spring_layout(G, k=1, seed=0)
plt.figure(figsize=[5, 5])
nx.draw(G, pos, node_size=70)
plt.show()
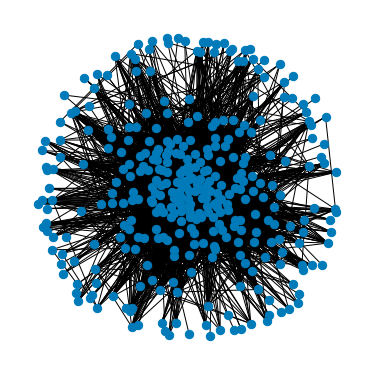
なんでしょうかこれは。コロナウイルスでしょうか。
全体を見ようとすると何も見えなくなるので、各ノードから一番一緒にいた人にだけエッジを繋げることにします。
top = hours_mat.rank(axis="columns", method="min", ascending=False) == 1
G = nx.from_numpy_array(top.astype(int).to_numpy())
pos = nx.spring_layout(G, k=0.1, seed=0)
plt.figure(figsize=[5, 5])
nx.draw(G, pos, node_size=40)
nx.draw_networkx_nodes(G, pos, nodelist=[0], node_size=300, node_color='red',
node_shape='*', label="おれ")
plt.legend(fontsize=20)
plt.show()
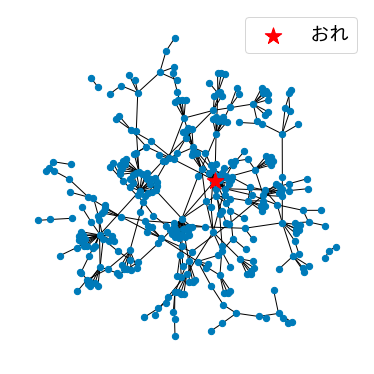
なんか構造が見えてきました。僕は密集しているところにいるみたいです。僕のいるところには人が集まるのでしょうか(なんつって)。
中心性
「密集しているところ」というと定性的ですが、中心性という指標で測ることもできます。
- 媒介中心性(betweenness centrality): 誰かと誰かの間にどのくらいよくいるか
- 近接中心性(closeness centrality): コミュニティ内の人との平均距離の近さ
中心性だけでもとてもいろんな種類があるみたいです。 NetworkX - Centrality
G = nx.from_numpy_array(1 / hours_mat.to_numpy())
closeness = (
pd.Series(nx.closeness_centrality(G, distance="weight"))
.set_axis(hours_mat.index, axis="index")
.sort_values(ascending=False)
)
betweenness = (
pd.Series(nx.betweenness_centrality(G, weight="weight"))
.set_axis(hours_mat.index, axis="index")
.sort_values(ascending=False)
)
weight は距離として扱われるので、大きいほど離れていると解釈されます。一緒にいた時間というのは大きい方が身近なので逆転する必要があります。ここではとりあえず適当に逆数をとりました。指標の計算にはそれぞれ 10 秒以上かかりました。339 個のノードについて最短経路問題を計算しているので、まあそんなもんかなという感じですね。
ここでダイクストラ法でゴリゴリ解いてました。[source]
気になる上位のメンバーは。。。
| 順位 | 媒介中心性 | 近接中心性 |
|---|---|---|
| 1 | おれ | おれ |
| 2 | akane | yo |
| 3 | yo | J |
| 4 | miharun | このぴー |
| 5 | ayato | ayato |
近接中心性の上位は DAWN をよく利用している人が多いです。一方、媒介中心性は人と人をつなぐようなはたらきが評価されやすい指標なので社員さんやコミュニティサポートの方が上位に多いです。
僕は DAWN 開いた時に適当に人がいる部屋に入ってるだけなので、
人と人をつなぐようなはたらきをした覚えはないです。
クラスタリング
次にクラスタリングをしてみます。クラスタリングは類似したサンプルをまとめる手法なのでサンプル同士の類似性さえ定義できれば適用することができます。
空間上なら点と点を足して2で割れば新たな点(重心)ができますが、人と人の距離を足して2で割っても新たなノードはできません。なので、KMeans のように重心をつかう手法は使えないといった、制限はあります。
見分け方としては fit メソッドの X の型に (n_samples, n_samples) があれば使えます。
AffinityPropagation は使える。

KMeans は使えない。
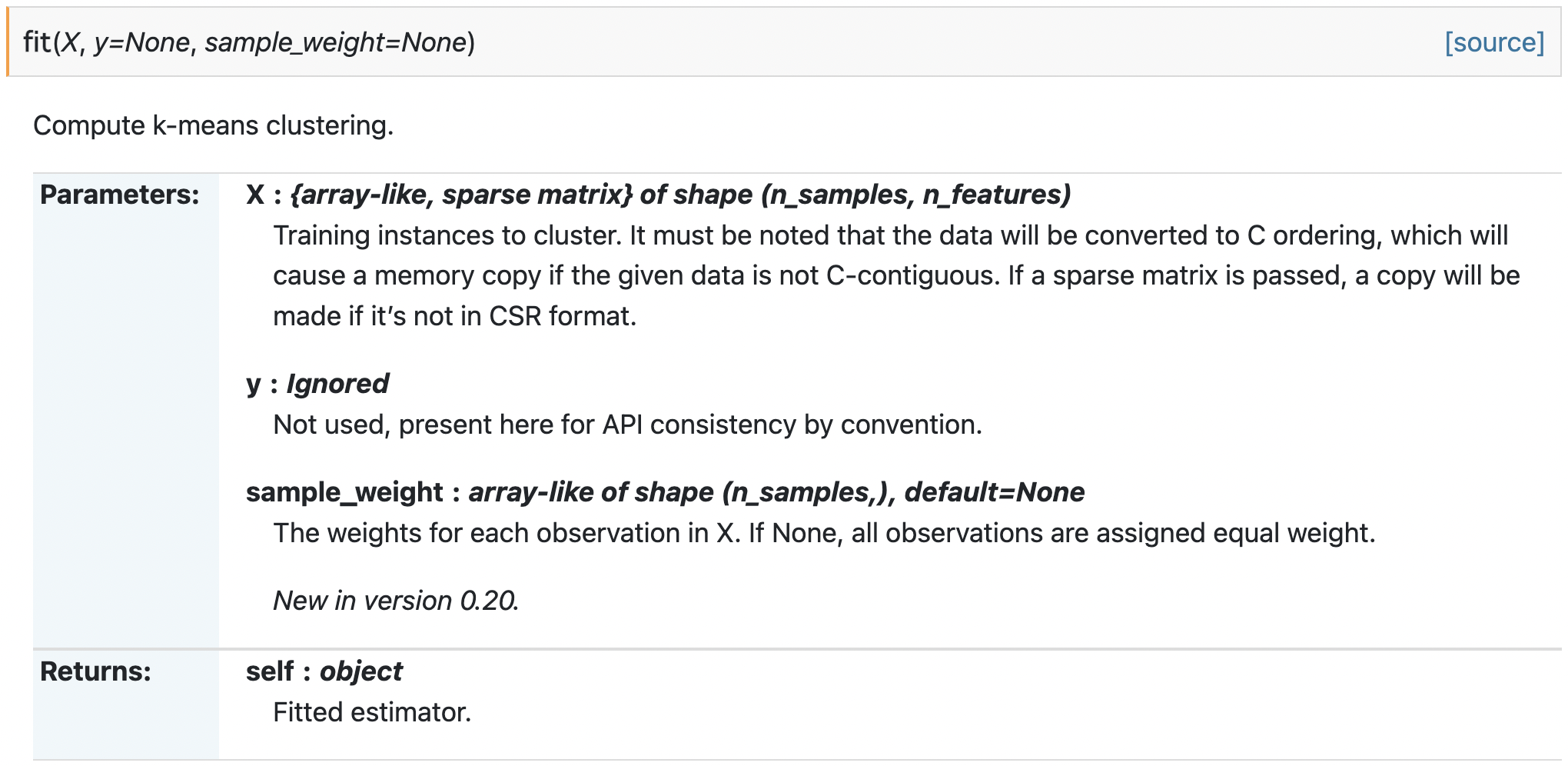
他にも目的に応じて色んな手法があります。sklearn.cluster
今回は AffinityPropagation の結果がきれいに出たのでこれについて話すことにします。
from sklearn.cluster import AffinityPropagation
clustering = AffinityPropagation(random_state=5, affinity='precomputed',
max_iter=100).fit(hours_mat)
# ここから下は Jupyter でいい感じに表示するためだけのコード
clusters = []
for label in np.unique(clustering.labels_):
clusters.append(hours_mat.index[clustering.labels_ == label].to_numpy())
df = pd.DataFrame(np.full([len(clusters), max(map(len, clusters))], ""))
for i, cluster in enumerate(clusters):
df.iloc[i, :len(cluster)] = cluster
with pd.option_context('display.max_columns', None):
display(df)
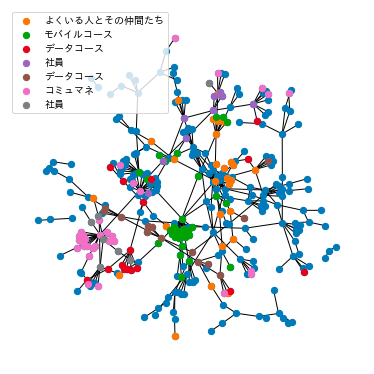
クラスタリングした結果、平均 12 人のクラスタが 28 個できました。
過去に Tech Blog で自己紹介してる人が多いクラスタだけ抽出してみました。(主観を含む)
| ひとこと | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| よくいる人とその仲間たち | おれ | J | このぴー | ayako | nacchan |
| モバイルコース | yo | TAK848 | shu | koshi | ... |
| データコース | sota | daichi | shunji | ... | ... |
| 社員 | miharun | kpppn | ryu | kaoru | kaito |
| データコース | ando | ishihira | wataru | ... | ... |
| コミュマネ | akane | andy | azuki | sacchan | ... |
| 社員 | CTO | CEO | k.shirai | ohnishi | hangai |
同じコースのメンバーはほぼ同じクラスタに割り当てられていて、新入生部屋と呼ばれる新入生が一緒に作業をする部屋を表しているようなクラスタなども見られました。さらに、同じコースでも講師と卒業生と受講生のクラスタはきれいに分かれたなーという印象でした。
驚くほどうまくいったのは AffinityPropagation がグラフのためのクラスタリング手法で、その計算過程もコミュニティの活動と似たことをしているからのようです。
AffinityPropagation creates clusters by sending messages between pairs of samples until convergence.(公式ドキュメントの User Guide より)
さっきのグラフをクラスタリングの結果で色付けするとこんな感じになりました。
desc = ["よくいる人とその仲間たち", "モバイルコース", "データコース", "社員", "データコース", "コミュマネ", "社員"]
for l in range(7):
nx.draw_networkx_nodes(G, pos, nodelist=np.arange(339)[clustering.labels_ == l],
node_color=np.array([cm.tab10(l + 1)]), node_size=40,
label=desc[l])
最後に
自分が分析対象に入ってるというのはレアな経験なので出力一つひとつが面白かったです。
今回の分析の目的は「テックブログのネタ」だったので言ってしまえばデータに手法を適用した結果を眺めただけでしたが、「コミュニティ活性化のためには何をすべきか」という実用的な目的を掲げると、こんな取り組みをしたら結果がこう変わりそうと仮説を立てて実際に行動を起こすことになります。なので、"最後に" というセクションですが実はスタート地点にも立っていないのかもしれません。
ちなみに無意識でしたが、僕って地の文では "僕" なのに記号としては "おれ" を使うんですね。





{kind=link}