
自己紹介
- 名前:yuuki
- 役職:ChatGPT調査担当
やりたいこと
- 学生や社員がChatGPTに対して興味を持ってもらったり触るハードルを下げる
- ChatGPTやLLMについて少し詳しくなれる
やること
対話形式でキャラクターが話しながら学んでいく物語をChatGPTで作成し記事にする
登場人物
- 兄者:怪しい関西弁
- 妹:今日は敬語なクーデレタイプ
今回のテーマ「Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets」
【兄者】おう、お前、ワシまた読んできたんやで。すげえ興味深いやつやね。
【妹】ええ、それは面白そうな論文なのかな?教えてくれる?
【兄者】おう、まずはテーマなんやけどな。この論文は、小さなアルゴリズム生成のデータセット上でニューラルネットワークの汎化能力について研究したって言うねん。データの効率性や記憶、汎化、学習速度などを詳しく分析することができるんやってさ。
【妹】なるほど、それは興味深いテーマだね。どのようにしてニューラルネットワークの汎化能力を研究しているの?
【兄者】この論文の著者たちは、データのパターンを理解するプロセスとして「grokking」という現象を調査してるねん。つまり、ネットワークが一定の訓練量の後に突然コンセプトを理解するということなんや。小さなアルゴリズムデータセットを使った実験を通じて、彼らはgrokkingが訓練データを完全に暗記する段階とは必ずしも一致しないことを発見したんや。つまり、ネットワークが暗記だけでなく汎化も可能なんやなってな。
【妹】なるほど、ネットワークが訓練データを暗記するだけでなく、理解もできるんだね。それって、汎化能力の向上にどう関係しているの?
【兄者】そのgrokking現象と汎化能力の関係を研究してるんや。具体的には、アルゴリズム生成の小さなデータセットにおける汎化とデータセットのサイズの関係を調べてるんやで。著者たちは、データセットのサイズが小さくなると、ネットワークが同等の汎化性能を達成するためにより多くの最適化ステップを必要とすることを見つけたんや。これは、データの制約性と小さなデータセット上での汎化を最大化するための最適化手法の重要性を強調してるんやで。
【妹】なるほど、データセットのサイズが小さいと、ネットワークはより多くの最適化ステップが必要なんだね。それは限られたデータの課題と最適化の関係を示していますね。
【兄者】そうやで、さらに、著者たちはトレーニングデータに外れ値を導入することの影響も調べてるんやで。意外にも、わずかな数の外れ値が汎化性能に大きな影響を与えないことが分かったんや。これは、ネットワークがノイズを効果的に除外して、本質的なパターンに焦点を当てる能力を持っていることを示しているんやな。それがgrokkingとも関係してると思われるねん。
【妹】なるほど、外れ値の導入が汎化性能に大きな影響を与えないのは興味深いですね。ネットワークがノイズを取り除いて、本質的なパターンに集中する能力があるんだね。それがgrokkingと関連しているというのは興味深い考えだね。
【兄者】そうやで、さらに、訓練中に見つかった最小値の鋭さが汎化との関連性についても研究してるんや。訓練中に見つかる最小値の鋭さが小さなアルゴリズムデータセット上での汎化能力を予測する指標になる可能性があるって著者たちは示してるんやで。これは、ネットワークの最適化空間と汎化の関係をさらに探るための重要な知見となっているんやで。
【妹】なるほど、最小値の鋭さが汎化能力の予測に役立つ可能性があるんだね。ネットワークの最適化空間と汎化の関係を理解することで、ネットワークのパフォーマンス向上や過学習の解決につながるかもしれないね。
【兄者】まとめると、この論文ではニューラルネットワークの汎化能力と特に小さなアルゴリズムデータセット上でのgrokking現象について探求してるんや。著者たちは、データセットのサイズや最適化の量と汎化の関係を調査する実験を行い、過学習を超えた汎化の改善が可能なことを示しているんや。また、外れ値の影響や最小値の鋭さと汎化との関係も研究しているんやで。論文では実験の詳細や図表も提供されており、関連研究についても議論されているんやで。
【妹】なるほど、この革新的な研究では、ニューラルネットワークのgrokking現象とその汎化能力に関する洞察が提供されていますね。小さなアルゴリズムデータセットを通じて、データ効率性や記憶、汎化、学習速度などの要素について詳細な分析が行われていますね。
【兄者】おお、お前もしっかりと理解しとるやんけ!これからのニューラルネットワークの研究において、grokkingという概念やデータセットのサイズ、外れ値の影響、最小値の鋭さという観点は重要な研究対象やと言えるねん。これらの側面を解明することで、より効率的で頑健な学習アルゴリズムの開発につながるやろうな。
【妹】まさにその通りですね。この研究は、小さなアルゴリズムデータセット上のニューラルネットワークの汎化能力についての私たちの理解を深める一助となるでしょう。grokkingの概念、データセットのサイズ、外れ値の影響、最小値の鋭さという要素は、さらなる研究の展開につながる重要なテーマです。これらを解明することで、より効率的で頑健な学習アルゴリズムの開発に一歩近づけることができるでしょう。
【兄者】おお、お前、上手にまとめとるやんけ!これからも一緒にニューラルネットワークの研究を追いかけていこうや!
【妹】はい、兄者!これからも一緒に勉強し、新たな知識を追求していきましょう!
補足 by 筆者
こちらの論文は、深層学習の中で起きる奇妙な現象の一つ、「Grokking」という現象について初めて報告されたものとなります。このGrokkingを一言で言うと、「過学習し始めてもずっと学習させ続けていたら突然汎用性が高くなった」という現象になります。
そもそも過学習とはなんぞやという話について、ざっくりとした説明しますと(気になったら調べてみてください!)、機械学習/深層学習では、未知のデータに対応できるように、まず訓練用データを学習いたします。その際に訓練用データを過剰に学習することで、「訓練用データに対する精度のみが向上し、未知のデータつまり検証用データへの対応精度と乖離が出る現象」が起き、その現象を過学習と呼びます。訓練用データを学習させすぎると、訓練用データに対した精度しか上がらず、他のデータへの精度が落ちて汎用性が落ちてしまうような感じです。
その前提で考えると、「過学習し始めてもずっと学習させ続けていたら突然汎用性が高くなった」という現象は、まさに逆転の発想のため注目を集めたわけです。また、この論文の著者がOpenAIの方ということもあり、ChatGPTの汎用性の高さの理由がここにあるのではないか、という見方も注目を集めた要因でしょう(私もそう聞いて読みました)。
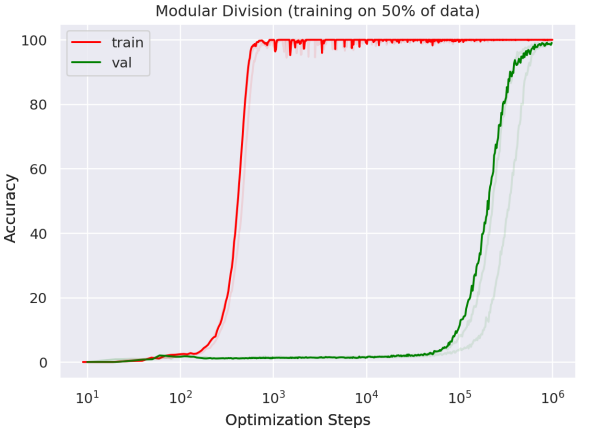
下記は論文内にある、Optimization steps(最適化された学習ステップ数)を横軸、Accuracy(精度)を縦軸にしたグラフです。
train(訓練データ)のAccuracyはOptimization stepsが10の3乗になる前くらいに100になり、val(検証データ)のAccuracyはOptimization stepsが10の5乗になる辺りから上昇し10の6乗あたりで100になります。trainとvalのAccuracyについて、Optimization stepsが10の2乗を超えたあたりから乖離が出ているため、そのあたりから「過学習」が起きていると言えます。そしてOptimization stepsが10の5乗を超えたあたりからvalのAccuracyが向上し、未知のデータであるvalに対してもtrainと同様に対応できるような汎用性が増した、「Grokking」が起きたということになります。
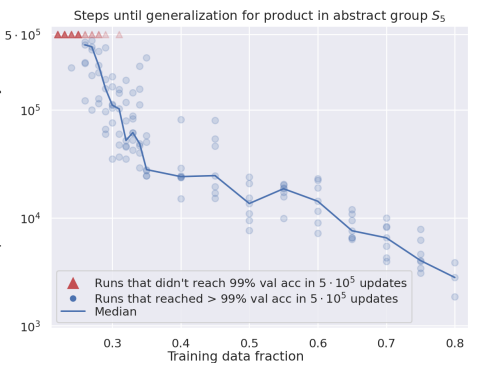
下記は同様の論文内にある、Training data fraction(訓練データの割合)を横軸に、Median steps to validation accuracy > 99%(精度が99%を超えるまでに必要なステップ数の中央値)を縦軸にし、訓練データの割合ごとに精度が99%を超えたらそのステップ数を青丸でプロット、99%に達しなければ赤▲でプロットしたグラフです。
これは、訓練データの割合を減らすと、検証データに対応できるようになるまでに必要なステップ数が多くなり、場合によっては99%の精度に達しなくなる、つまり学習するデータ量を減らすと汎用性が低下することを表しています。
あとがき
今回まとめたのはGrokkingと呼ばれる現象について書かれた論文を紹介いたしました。補足ではGrokkingがざっくりとでも分かっていただけるよう2図を使って説明いたしました。実はほかにも二項演算についてであったり、より難しい内容も書かれているので、レベルアップしたい方はぜひ引用元を御覧ください!





{kind=link}