
データサイエンスコースのIshihiraです。現在参加している自然言語処理のプロジェクトでSentenceBERTというモデルを使う機会がありました。
コース内で開催している深層学習(MLP)の勉強会でたまたま関連する内容を勉強していたので、実際使ってみた結果と合わせて記事にしてみました。
距離計量学習とは
データxをコンパクトな特徴yに移す写像の中で、yの空間での距離がデータxの類似度を表すようなものを学習する方法です。(「深層学習」より引用)
やさしい説明
「深層学習」の説明をいきなり読んでも全くピンと来ないので
- データxをコンパクトな特徴yに移す写像
- yの空間での距離がデータxの類似度を表す
の2項目に分けて考えてみましょう。
以下では2つ顔画像を入力したら2つの顔が「同じ人の顔」か「違う人の顔」か判定してくれるモデルを考えます。
深層学習モデルは通常、次元の大きい入力(=データx)を受け取って、それを端的に表現した短いベクトルに「要約」しています。こうして作られるベクトルが「コンパクトな特徴y」です。
下画像の例では左の人の顔写真が「データx」、右の4次元ベクトルが「コンパクトな特徴y」ですね。
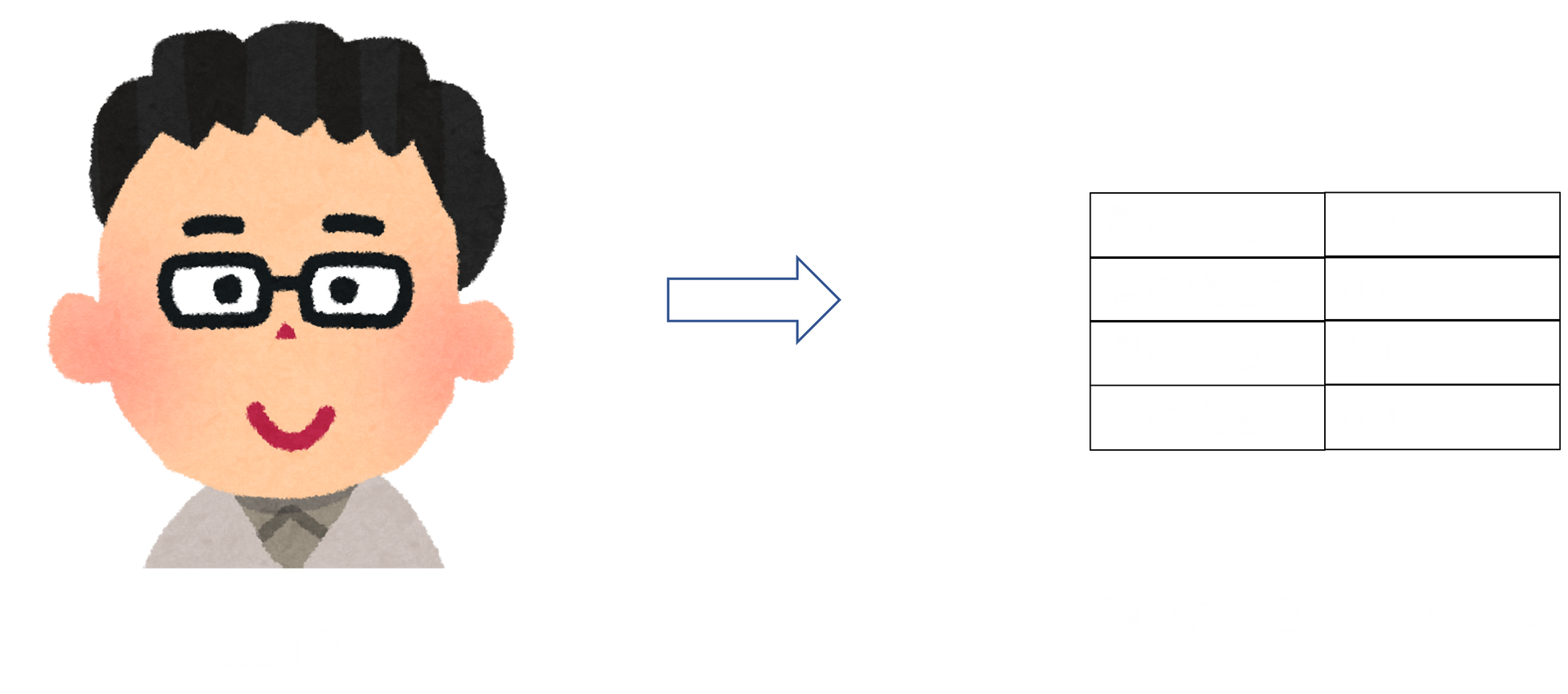
こうして特徴を表現するベクトルが得られたあと、2つのデータxが同じ人の顔かどうか判定するために「2つの特徴ベクトルyの近さ」を利用します。
データxの要約であるベクトルyどうしが近いほどデータxは似ているはずだと考えるわけです。
この思想のもと、距離計量学習では「ベクトルの近さ」を距離(L2ノルム)で表現します。これが「yの空間での距離がデータxの類似度を表す」の意味です。
損失関数
「損失関数」とはモデルの予測がどれくらい悪いかを表す指標で、深層学習モデルはこれを減らすように学習していきます。したがって、解きたいタスクに最適化させるにはそれに見合った損失関数の設計が必要です。
モデルが行う写像を
$$\bold y = f(\bold x)$$
と定義します。
今回のyは$(\bold x_i, \bold x_j)$ について$i=j$なら$(\bold y_i, \bold y_j)$は近くに、$(\bold x_i, \bold x_j)$ について$i \neq j$なら$(\bold y_i, \bold y_j)$は遠くにあってほしいです。
したがって損失関数$E(\bold w; \bold x_i, \bold x_j)$もそういった性質を反映させて
$$\begin{equation}E(\bold w; \bold x_i, \bold x_j) = \begin{dcases}||\bold y_i - \bold y_j||^2_2 & (i = j) \\ m - ||\bold y_i - \bold y_j||^2_2 & (i \neq j)\end{dcases} \end{equation}$$
とします($\bold w$はモデルのパラメータです)。
mはマージンと呼ばれており、モデルの使用者が決める値です。これがあることで異なるクラスxからベクトル化されたベクトルyどうしが過剰に離れないようになっています。
(本当は距離計量学習の損失関数、学習法は他にもいろいろありますが、多くは上記の方法の派生版として理解できます)
実際にSentenceBERTを触ってみる
SentenceBERTについての解説はこちら
今回はJSTSを用いてSentenceBERTが意味の近さを捉えられているか評価してみようと思います。
JSTSとは
"STS"とは"Semantic Textual Similarity"(意味的文章類似度)の略で、「2つの文章の意味的な類似度を評価する」というタスクのことを指します。
もとは英語圏で定義された言葉であり、英語向け自然言語処理データセットの"GLUE"に"STS"という項目が含まれています。
JSTS(Japanese STS)という名前は、それと区別する意図で命名されたものと思われます。
実際のデータはこんな感じです
{"sentence_pair_id": "691",
"yjcaptions_id": "127202-129817-129818",
"sentence1": "街中の道路を大きなバスが走っています。",
"sentence2": "道路を大きなバスが走っています。"
"label": "4.4"}
"label"の項目が2つの文章の類似度を表しており、"label"は0~5の実数値をとっています。
実験の概要
sonoisaさんが事前学習済みモデルの重みファイルとすぐ使えるコードを公開してくださっています。自分もその恩恵にあずかり、クラス定義部分はコピペしました。実行用のコードはこちら。実行環境はGoogle Colabです。
評価方法ですが、今回は相関係数を用いてみようと思います。具体的には下記の流れです。
- SentenceBERTで2文をベクトル化
- 2つのベクトルの距離を算出
- 1, 2をデータセット全てに対して行う
- 得られた距離とデータセットの"label"の相関係数を計算する
- 得られた距離とデータセットの"label"を散布図にプロットしてみる
算出される値に関して
- SentenceBERT:意味が類似しているほど距離が小さい
- STSの"label":意味が類似しているほどスコアが大きい
となっているので、SentenceBERTの意味類似度計算機としての性能は相関係数が-1に近いほど良いと言えます。
なお、計算された距離は[0, 5]に収まるようにスケーリングされています。
実験結果
相関係数:-0.84218
結果のグラフは下図のようになりました。
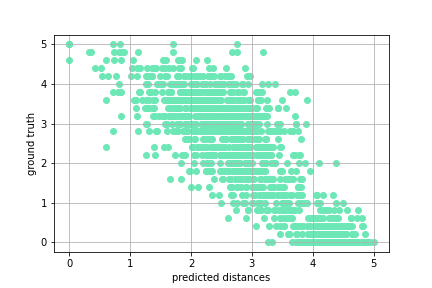
パッと見なかなかよさそうな結果になりました。
とはいえ、実際使うことを考えるとlabel=5に対する距離が2以上になっているケースがあるなど、気になる点がいろいろありますね。
ところでプロットしてみてわかったことですが、JSTSの"label"は実数値をとると言いつつ、必ず"label"$\in \{0.0, 0.2, 0.4,..., 4.8, 5.0\}$が成り立っているみたいです。



{kind=link}