
こんにちは.バックエンドの藤岡です.私は学部4年生として案件と卒研に追われる日々を過ごしております.そんな中,専攻している深層学習(所謂AIですね)でGPU不足に悩んだので,備忘録としてその経緯と対処法について書いていきます.
「深層学習を少し知っているよ」くらいの方に向けてに書いたつもりですが,専門用語やコードを用いた説明は避けたので「深層学習?なにそれおいしいの?」という方でも気楽に読んでもらえればと思います.もしこのブログがどなたかの役に立てられれば幸いです.
はじめに
私は卒業研究として,『時系列モデルを用いた画像圧縮』というテーマで研究をしております.これをさっくり説明すると,『AIを使って画像情報を小さくする』というものです.そのために,日夜深層学習モデルの学習と改良を繰り返しているわけですが,遂に私にもこの時が来てしまいました.

GPUが足りないというエラー文です.コード実装中は動作確認用としてデータセットとしてサイズの小さい画像のみを扱ってきたのですが,本番用の比較的大きな画像サイズのデータセットを使ってみたら,ものの見事にGPUが足りなくなりました.
実際にはどれほど足りないのか軽く計算してみました.
デバッグで小さいサイズの画像(32×32)で学習させていたときは,学習におよそ5GB使用していました.この情報を元に本番用のデータセットの画像サイズ(224×224)にしたらどれほどGPUが増えるかを試算します.私が研究に採用した深層学習モデルのS4[1](以下モデルと呼称)は,計算時のメモリ使用は,モデルの次元をNとし,入力長をLとしたときO(N+L)に従います(要はモデルの次元数と入力の長さの足し算分メモリを使うという訳です).そのため,画像サイズ32×32から224×224にサイズアップすると,Lが7×7=49倍になるという訳です.そのため,仮にNがLに対して十分小さいとすると,本番用のデータセットの学習では5GB×49≒250GBくらい必要になるということです.私が使用している研究室のサーバーのGPUは,1基あたりのGPU容量がおよそ50GBですので,これでは全然足りないことがわかります.
では,どのようにメモリを削減したのか,以下で記述します.
ハイパーパラメータの調整
まず真っ先に取り掛かったのが,モデルのハイパーパラメータ(以降ハイパラと呼称)の調整です.先程記述した通り,モデルのGPU使用はO(N+L)に従います.画像のサイズアップでLが49倍になったのなら,それに伴いNを削減したらよいという発想です.
ですが,もちろんこれだけでは十分とは言えません.加えて,この方法は本来であればあまり取りたくない手段です.学習の画像サイズが増えれば,その分モデルにはより繊細な表現を学習してくれることを期待します.そして,この"繊細な表現"は一般的にNが増えるほど可能になります(厳密にはそうとは言い切れないのはここでは省略します).そのため,いくらメモリ削減のためとはいえ,あまりNを削りたくはないものです.
バッチサイズの調整
次に目をつけたのが,バッチサイズの調整です.
ここで,バッチサイズを初めて聞いた方に簡単に説明します.深層学習では学習測度向上や学習の安定化のために学習データをある程度の数でひとまとまりにして学習します.例えると,"小学生"という概念を学習したいモデルに全国の小学生の顔写真を1枚1枚見せて学習させると大変な労力になりますので,1クラス分一気に見せて学習させる,といったイメージです.
バッチサイズを小さくすると,直接的にLを小さくすることができます.そこで,デフォルトのバッチサイズ64から徐々に小さくしていき,どこで50GBに収まるか見てみました.32くらいであれば許容範囲内です.試してみた結果...
収まったのはバッチサイズ2のときでした...😭
これでは学習に時間がかかりすぎる上,まともに学習できるとは思えません.そこで,最後に以下のことをしました.
Accumulated Gradientsの導入
Accumulated Gradientsはモデルのパラメータ更新を複数回分まとめて行うというGPU削減の手法です.詳しい説明はまた別の機会に回すとして,簡単にイメージを説明しますと,数学の問題を小問ごとに区切れば,1問あたりに使う紙の量は減るよねと言う感じです(もうちょっとわかる人向けに説明すると,勾配計算を特定の数で分割,それらをまとめて勾配更新することによって,モデル内で保持する膨大な量の潜在特徴量を削減できるという訳です.)
このAccumulated Gradientsを導入し,色々とハイパラを調整した結果...
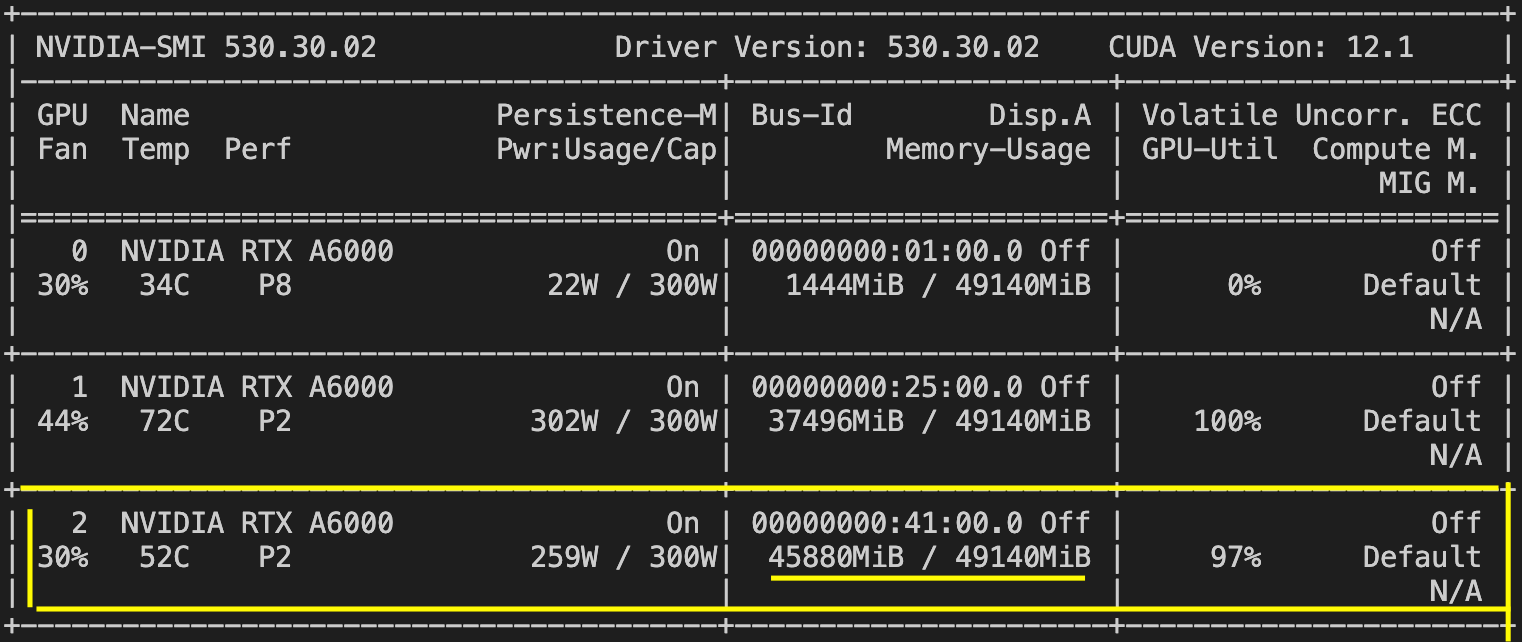
なんとか45GBまで圧縮し,50GB内で動くようになりました.🙌
最後に
これでめでたく本番用のデータセットで学習ができると息巻いてコードを実行してみた結果,すべての学習が終わるまでの見込み時間がなんと,
4 0 0 0 時 間 で し た . . . 😭
およそ5.5ヶ月です.とっくに卒業していますね.深層学習というのは大変な分野です.

![[Flutter] 学内手渡しのフリマアプリを作っている話](/content/images/size/w1200/2023/12/-------------1.png)



{kind=link}